


"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
서론
데이터를 시각화하는 것은 데이터를 이해하는 데 있어 매우 중요한 과정입니다. 여러 가지 종류의 그래프를 그리는 방법에 대해 알아보겠습니다. 파이썬에서 데이터 시각화를 위해 주로 사용하는 라이브러리는 matplotlib와 seaborn입니다. 이 두 라이브러리를 함께 사용하면 다양한 그래프를 그릴 수 있습니다. 또한, 싸이킷런(scikit-learn)의 내장 데이터를 사용하여 예제를 제공하겠습니다.
1. Scatter Plot (산점도)
산점도는 두 변수 간의 관계를 시각화하는 데 사용됩니다. 아래의 코드는 싸이킷런의 '붓꽃' 데이터 세트를 사용하여 피처 'sepal length (cm)'와 'sepal width (cm)' 사이의 관계를 시각화합니다. plt.scatter는 matplotlib 라이브러리의 함수로, 두 변수 간의 관계를 시각화하는데 사용됩니다. x축과 y축에 각각 하나의 변수를 할당하여 두 변수 간의 상관관계를 산점도로 나타냅니다. 이는 두 변수 간의 관계를 직관적으로 파악하기 위해 사용됩니다.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
iris = load_iris()
data = iris.data
target = iris.target
plt.scatter(data[:, 0], data[:, 1], c=target)
plt.xlabel('sepal length (cm)')
plt.ylabel('sepal width (cm)')
plt.show()
sns.pairplot은 seaborn 라이브러리의 함수로, 데이터프레임의 모든 변수 쌍에 대한 산점도를 그립니다. 이는 여러 변수 간의 상관관계를 한 눈에 파악하기 위해 사용됩니다. 대각선 위치에는 각 변수의 히스토그램 또는 KDE(커널 밀도 추정) 그래프가 그려집니다.
import seaborn as sns
from sklearn.datasets import load_iris
import pandas as pd
# Iris 데이터 로드
iris = load_iris()
data = iris.data
target = iris.target
features = iris.feature_names
# 데이터프레임 생성
df = pd.DataFrame(data, columns=features)
df['target'] = target
# pairplot 그리기
sns.pairplot(df, hue='target', vars=features)
plt.show()2. Histogram (히스토그램)
히스토그램은 변수의 분포를 시각화하는 데 사용됩니다. 아래의 코드는 'sepal length (cm)'의 분포를 히스토그램으로 시각화합니다.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
iris = load_iris()
data = iris.data
target = iris.target
plt.hist(data[:, 0], bins=30)
plt.xlabel('sepal length (cm)')
plt.ylabel('frequency')
plt.show()
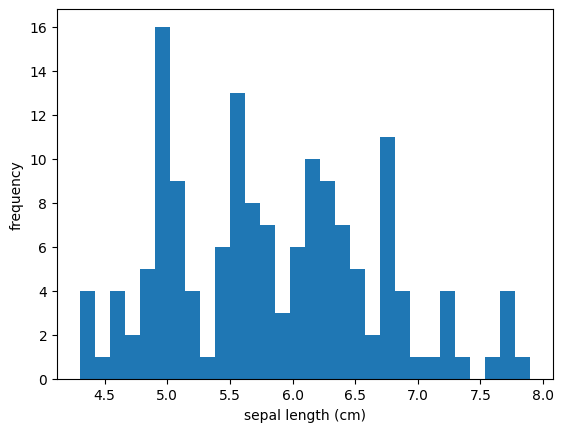
3. Box Plot (상자 그림)
상자 그림은 변수의 중앙값, 사분위수, 이상치를 한 눈에 보여주는 그래프입니다. 아래의 코드는 'sepal length (cm)'의 상자 그림을 그립니다.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import pandas as pd
# Iris 데이터 로드
iris = load_iris()
data = iris.data
features = iris.feature_names
# 데이터프레임 생성
df = pd.DataFrame(data, columns=features)
# Box plot 그리기
plt.figure(figsize=(10, 6)) # 그래프 크기 설정
df.boxplot()
plt.title('Box plot of Iris dataset') # 제목 설정
plt.xticks(rotation=45) # x축 레이블 기울기 조절
plt.show()
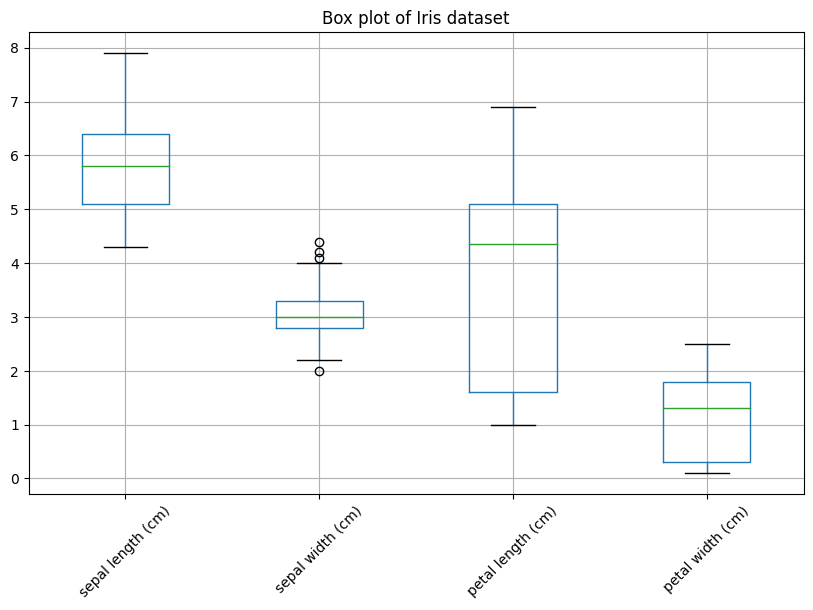
4. Line Plot (선 그래프)
선 그래프는 시간에 따른 변수의 변화를 시각화하는 데 주로 사용됩니다. 아래의 코드는 'sepal length (cm)'의 변화를 선 그래프로 시각화합니다.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import pandas as pd
# Iris 데이터 로드
iris = load_iris()
data = iris.data
features = iris.feature_names
# 데이터프레임 생성
df = pd.DataFrame(data, columns=features)
# 선 그래프 그리기
fig, axs = plt.subplots(len(features), figsize=(10, 12)) # subplot 생성
for i, feature in enumerate(features):
axs[i].plot(df[feature]) # 각 feature의 선 그래프 그리기
axs[i].set_title(feature) # 각 subplot의 제목 설정
plt.tight_layout() # 그래프 간격 조절
plt.show()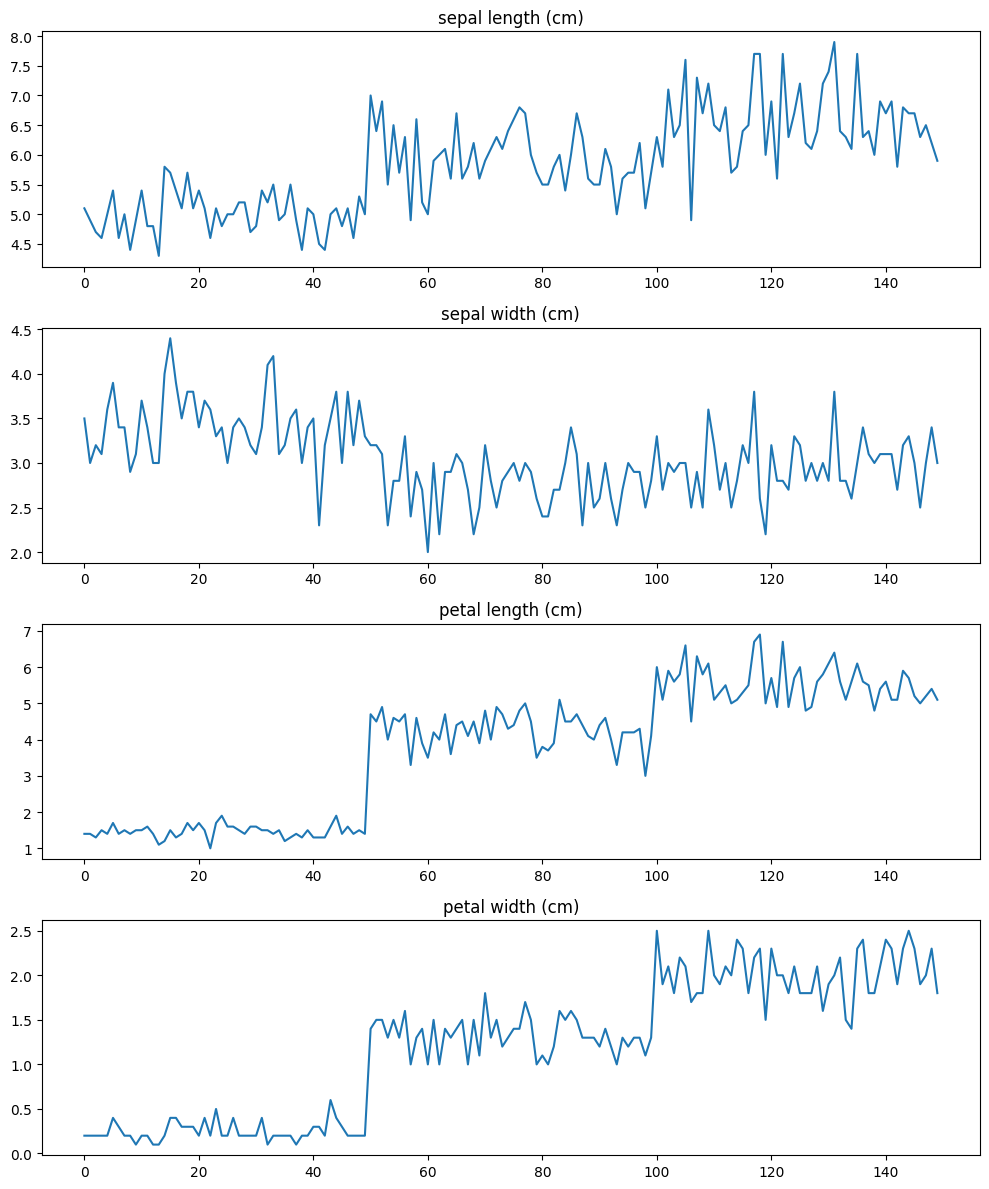
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import pandas as pd
# Iris 데이터 로드
iris = load_iris()
data = iris.data
features = iris.feature_names
# 데이터프레임 생성
df = pd.DataFrame(data, columns=features)
# 선 그래프 그리기
plt.figure(figsize=(10, 6)) # 그래프 크기 설정
for feature in features:
plt.plot(df[feature], label=feature) # 각 feature의 선 그래프 그리기
plt.title('Line plot of Iris dataset') # 제목 설정
plt.legend() # 범례 표시
plt.show()
5. heatmap(상관계수 분석)
이 코드는 Iris 데이터의 각 feature 간의 상관계수를 계산하고, 이를 히트맵으로 그립니다. annot=True는 각 셀에 숫자를 표시하라는 의미이며, cmap='coolwarm'은 색상 팔레트를 설정하는 부분입니다. 이를 통해 각 feature 간의 상관관계를 쉽게 파악할 수 있습니다.
상관계수는 -1에서 1까지의 값을 가지며, 1에 가까울수록 강한 양의 상관관계, -1에 가까울수록 강한 음의 상관관계를 가집니다. 0에 가까우면 두 변수 간의 상관관계가 약하다는 것을 의미합니다.
import seaborn as sns
from sklearn.datasets import load_iris
import pandas as pd
# Iris 데이터 로드
iris = load_iris()
data = iris.data
features = iris.feature_names
# 데이터프레임 생성
df = pd.DataFrame(data, columns=features)
# 상관계수 행렬 계산
corr_matrix = df.corr()
# 히트맵 그리기
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm')

6. 파이차트
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
# Iris 데이터 로드
iris = load_iris()
data = iris.data
target = iris.target
# 데이터프레임 생성
df = pd.DataFrame(data)
df['target'] = target
# 'target' 변수의 각 클래스별 비율 계산
class_ratio = df['target'].value_counts(normalize=True)
# 파이 차트 그리기
plt.pie(class_ratio, labels=iris.target_names, autopct='%1.1f%%')
plt.title('Pie chart of Iris dataset')
plt.show()

마치며
데이터를 분석하고 이해하는 과정인 탐색적 데이터 분석(EDA)에서는 데이터의 특성에 따라 적합한 그래프를 선택하는 것이 중요합니다. 아래는 상황에 따른 그래프 선택을 돕는 모식도입니다.
1. 변수의 수
- 단일 변수 : 히스토그램, 박스 플롯
- 두 변수 : 산점도, 선 그래프
- 세 변수 이상 : 산점도 행렬, 히트맵
2. 변수의 유형
- 숫자형 변수 : 히스토그램, 박스 플롯, 산점도, 선 그래프
- 범주형 변수 : 막대 그래프, 파이차트
3. 변수 간의 관계
- 상관관계 : 산점도, 산점도 행렬, 히트맵
- 시간에 따른 변화 : 선 그래프 4. 데이터의 분포 파악
- 전체 분포 : 히스토그램, 박스 플롯
- 그룹별 분포 : 산점도(색상을 이용한 그룹 구분), 박스 플롯(그룹별)
데이터의 특성과 분석 목적에 따라 적합한 그래프를 선택하면 데이터를 더 효과적으로 이해하고, 인사이트를 발견할 수 있습니다. 이 모식도를 참고하여 EDA를 진행해 보세요. 이처럼 matplotlib와 seaborn을 활용하면 다양한 그래프를 그릴 수 있습니다. 여기서 제공된 코드는 템플릿으로 사용할 수 있으며, 필요에 따라 적절히 수정하여 사용하면 됩니다. 이러한 그래프들은 데이터의 특성을 이해하는 데 매우 유용하며, 머신러닝 모델의 성능 개선에 도움이 될 수 있습니다.
블로그 인기글
FT-IR의 원리와 활용
서론 적외선 분광법은 화학 분석 분야에서 필수적인 도구로 자리 잡았습니다. 특히, Fourier Transform Infrared Spectroscopy(FT-IR)는 그 중에서도 뛰어난 해석력과 사용의 편리함으로 인해 다양한 산업에서 널리 활용되고 있습니다. 본문에서는 FT-IR의 기본 원리와 함께, 이 기술이 어떻게 다양한 측정 방식으로 확장되어 식품 포장 재질 분석 등에 적용될 수 있는지를 설명합니다. 이를 통해 FT-IR이 식품 산업에서 어떤 방식으로 기여할 수 있는지, 그리고 식품 포장지의 재질을 식별하고 분석하는 과정에서 이 기술이 어떻게 사용되는지에 대한 깊이 있는 이해를 제공합니다. FT-IR(Fourier Transform Infrared Spectroscopy)은 적외선 분광법의 일종으..
10yp.tistory.com
자급제 + 알뜰폰 vs 통신사 비교 체험 후기 및 총정리
서론 스마트폰과 함께 우리의 일상을 더욱 풍요롭게 만드는 것이 바로 통신 서비스입니다. 통신비는 매달 지출되는 고정 비용 중 하나로, 많은 이들이 부담을 느끼곤 합니다. 이에 따라 비용을 절약하면서도 원활한 통신 서비스를 이용하고자 하는 소비자들의 관심이 자급제 스마트폰과 알뜰폰 요금제로 쏠리고 있습니다. 한편, 기존 대형 통신사들 또한 다양한 요금제와 부가 서비스를 제공하며 경쟁력을 갖추기 위해 노력하고 있습니다. 본문에서는 자급제 스마트폰을 선택하는 경우의 이점과, 알뜰폰 요금제의 장단점을 살펴보고, 기존 통신사 요금제와의 차이점을 비교해 보겠습니다. 자급제 + 알뜰폰 vs 통신사 비교 체험 후기 및 총정리 필독 휴대폰 사용을 위해서는 두가지가 필요합니다. 첫번째는 휴대폰, 두번째는 통신사 입니다...
10yp.tistory.com
'데이터 사이언스 > 기초' 카테고리의 다른 글
| 딥러닝(Deep Learning) - 핵심 개념 (3) | 2024.01.31 |
|---|---|
| 딥러닝(Deep Learning) 기초 (50) | 2024.01.30 |
| 머신러닝(Machine Learning) 데이터 스케일링 기초 (41) | 2023.12.07 |
| 머신러닝(Machine Learning) 데이터 인코딩(Encoding) 기초 (50) | 2023.12.05 |
| 머신러닝Machine Learning 알고리즘 라이브러리 싸이킷런scikit-learn (69) | 2023.12.01 |