


"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
머신러닝 전반전
탐색적 데이터 분석(EDA): 데이터 파악 → 데이터 전처리: 결측치, 이상치 수정
→ 데이터 인코딩: 데이터 변환 → 데이터 스케일링: 데이터 정규화
서론
데이터 분석을 위해 탐색적 데이터 분석(EDA)를 수행하면 데이터의 문제가 있을 경우 전처리를 진행합니다. 이는 기존 데이터를 분석 가능한 형태로 변환하는 과정으로, 결측치 처리, 이상치 제거 등의 작업을 포함합니다. 이러한 작업은 데이터의 품질을 향상시키고, 분석의 정확성을 높이는 데 중요한 역할을 합니다.
데이터 전처리는 종종 '데이터 클리닝'이라고도 불리며, 이는 데이터가 불완전하거나, 부정확하거나, 관련 없거나, 오류가 있는 경우 이를 수정하거나 제거하는 과정을 의미합니다. 이 과정은 데이터의 품질을 향상시키고, 데이터 분석의 결과를 더 신뢰할 수 있게 만듭니다.
이 글에서는 인코딩과 같은 추상적인 전처리 과정을 제외하고, 더욱 물리적인 전처리 과정에 초점을 맞춥니다. 결측치를 채워 넣는 방법, 결측치가 있는 행을 제거하는 방법, 이상치를 제거하는 방법 등에 대해 알아보겠습니다. 이러한 전처리 작업은 데이터를 깔끔하게 만들어 분석 과정을 원활하게 진행할 수 있게 돕습니다.
데이터 전처리는 복잡하고 시간이 많이 소요되는 작업일 수 있지만, 이는 결국 더 정확하고 신뢰할 수 있는 분석 결과를 얻기 위한 필수적인 과정입니다. 따라서, 이 글을 통해 머신러닝(Machine Learning) 전반전 - 데이터 전처리 실습을 진행하고, 데이터 전처리의 중요성을 이해하며, 실제 데이터 전처리 작업을 수행하는 방법에 대해 알아보는 시간을 갖도록 하겠습니다.
데이터 전처리
데이터 전처리는 데이터 분석의 중요한 단계로, 결측치 처리, 이상치 처리, 불필요한 피처 삭제 등의 작업을 포함합니다. 이러한 작업을 통해 데이터의 품질을 향상시키고, 분석의 정확성을 높일 수 있습니다.
1. 결측치 처리: 데이터에서 결측치를 발견한 경우, 이를 적절하게 처리해야 합니다. 결측치를 처리하는 방법은 여러 가지가 있지만, 가장 간단한 방법은 평균, 중앙값, 최빈값 등으로 대체하거나, 결측치가 있는 행을 삭제하는 것입니다. 아래는 결측치 처리 코드입니다.
#결측치가 있는 행 출력하기
print(df[df.isnull().any(axis=1)])
#특정 열의 결측치가 있는 행 출력하기
print(df[df['column_name'].isnull()])
# 평균으로 결측치 대체하기
df['column_name'].fillna(df['column_name'].mean(), inplace=True)
# 결측치가 있는 행 삭제하기
df.dropna(subset=['column_name'], inplace=True) #행 삭제 시 모든 열의 동일한 행이 삭제됨
# 결측치가 있는 열 삭제하기
df.dropna(axis=1, inplace=True)
2. 이상치 처리: 이상치는 데이터 분석의 정확성을 해칠 수 있으므로, 이를 적절하게 처리해야 합니다. 이상치를 발견한 경우, 이를 제거하거나, 다른 값으로 대체하는 등의 방법이 있습니다. 아래는 IQR을 이용한 이상치 처리 코드입니다.
# IQR을 이용한 이상치 제거하기
Q1 = df['column_name'].quantile(0.25)
Q3 = df['column_name'].quantile(0.75)
IQR = Q3 - Q1
df = df[~((df['column_name'] < (Q1 - 1.5 * IQR)) | (df['column_name'] > (Q3 + 1.5 * IQR)))]위의 코드처럼 이상치를 제거하거나 혹은 아래 코드처럼 특정 값으로 이상치를 대체할 수 있습니다.
# 이상치를 중앙값으로 대체
df.loc[(df['column_name'] < (Q1 - 1.5 * IQR)) | (df['column_name'] > (Q3 + 1.5 * IQR)), 'column_name'] = df['column_name'].median()
이상치로 분류하는 방법은 그 데이터의 형태와 문제 정의에 따라서 맞춰 사용하여야합니다. 이상치로 판단하는 것에 대한 기준은 추후 케이스들을 다뤄보도록 하겠습니다.
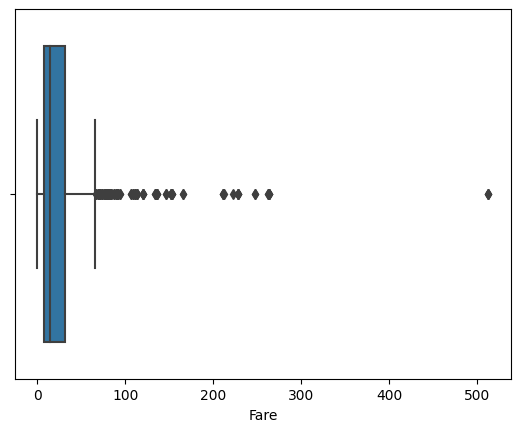
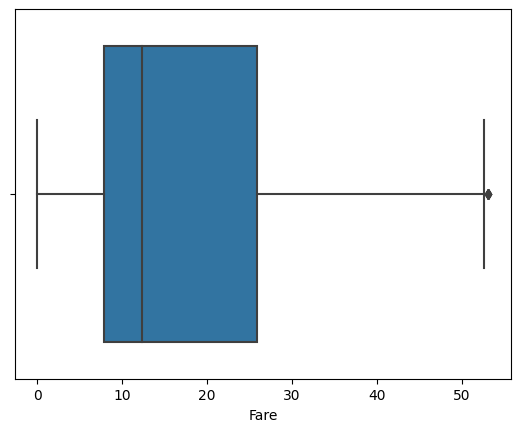
이상치 처리 전, 이상치 처리 후 Boxplot의 형태를 보았을 때 점으로 표시되는 이상치가 사라졌음을 확인할 수 있습니다.
Boxplot을 불러오는 코드는 이전 글 머신러닝(Machine Learning) 탐색적 데이터 분석(EDA) 실습 (tistory.com)을 참고해주시길 바랍니다.
머신러닝(Machine Learning) 탐색적 데이터 분석(EDA) 실습
서론 탐색적 데이터 분석(Exploratory Data Analysis, EDA)는 데이터 분석의 첫 걸음으로, 복잡한 데이터 세트를 이해하는 데 도움이 되는 방법입니다. 이 방법은 데이터의 주요 특성, 패턴, 예외, 그리고
10yp.tistory.com
3. 불필요한 피처 삭제: 결측치나 이상치가 너무 많거나, 분석에 필요하지 않은 피처는 삭제하는 것이 좋습니다. 이를 통해 데이터의 복잡성을 줄이고, 분석의 정확성을 높일 수 있습니다. 아래는 원하는 피처를 삭제하는 코드입니다.
# 불필요한 피처 삭제하기
df.drop('column_name', axis=1, inplace=True)결론
머신러닝(Machine Learning) 전반전 - 데이터 전처리 실습을 진행하였습니다. 이 글에서 데이터 전처리의 중요성과 그 과정을 살펴보았습니다. 결측치 처리, 이상치 제거 등의 전처리 작업을 통해 데이터의 품질을 향상시키고, 분석의 정확성을 높일 수 있음을 다뤘습니다. 이러한 과정은 복잡하고 시간이 많이 소요될 수 있지만, 이는 결국 더 정확하고 신뢰할 수 있는 분석 결과를 얻기 위한 필수적인 과정입니다.
오늘의 내용은 데이터 전처리의 물리적인 부분에 초점을 맞추었지만, 다음 시간에는 이보다 더 복잡한 전처리 과정인 인코딩에 대해 알아볼 예정입니다. 인코딩은 카테고리형 데이터를 숫자형 데이터로 변환하는 과정으로, 머신러닝 알고리즘이 이해할 수 있는 형태로 데이터를 변환하는데 필요합니다.
이는 오늘 다룬 결측치 처리나 이상치 제거와 같은 전처리 작업과 함께 데이터 분석의 성공을 결정짓는 중요한 과정입니다. 해당 글과 다음 시간에 작성할 내용은 모두 데이터 분석의 시작점으로 데이터 전처리 과정입니다. 이는 기존 데이터를 분석 가능한 형태로 변환하는 과정으로, 이를 통해 데이터의 품질을 향상시키고, 분석의 정확성을 높일 수 있습니다. 해당 내용을 잘 이해하고 인코딩에 대해 알아보는 것이 중요합니다.
'데이터 사이언스 > 머신러닝 실습 전반전' 카테고리의 다른 글
| 머신러닝(Machine Learning) 실전 데이터 전처리 (74) | 2023.12.29 |
|---|---|
| 머신러닝(Machine Learning) 실전 탐색적 데이터 분석(EDA) (5) | 2023.12.27 |
| 머신러닝(Machine Learning) 전반전 - 데이터 스케일링 실습 (49) | 2023.12.08 |
| 머신러닝(Machine Learning) 전반전 - 인코딩(Encoding) 실습 (57) | 2023.12.06 |
| 머신러닝(Machine Learning) 전반전 - 탐색적 데이터 분석(EDA) 실습 (58) | 2023.12.03 |