


"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
머신러닝 전반전
탐색적 데이터 분석(EDA): 데이터 파악 → 데이터 전처리: 결측치, 이상치 수정
→ 데이터 인코딩: 데이터 변환 → 데이터 스케일링: 데이터 정규화
서론
데이터 과학의 세계에서, 정보를 효과적으로 표현하고 이해하는 것은 매우 중요한 과제입니다. 이러한 과제를 해결하는 방법 중 하나가 바로 '인코딩'입니다. 인코딩은 간단히 말해 데이터를 컴퓨터가 이해할 수 있는 형태로 변환하는 과정입니다. 이는 문자열, 숫자, 날짜 등 다양한 형태의 데이터를 컴퓨터가 처리할 수 있는 형식으로 변환하는 것을 포함합니다. 이 과정은 데이터 분석 및 머신러닝에서 핵심적인 역할을 하며, 모델의 성능을 크게 좌우할 수 있습니다. 이런 중요한 인코딩 중에서도 '원-핫 인코딩'은 특히 주목받는 방법 중 하나입니다.
원-핫 인코딩은 범주형 데이터를 표현하는 데 매우 효과적인 방법으로, 각 범주를 독립적인 이진 변수, 즉 '0'과 '1'로 표현하는 방식입니다. 이 방법은 범주형 데이터를 머신러닝 알고리즘이 이해할 수 있는 형태로 변환하는 데 매우 유용합니다. 이 글에서는 인코딩의 기본 개념과 그 중요성, 그리고 원-핫 인코딩에 대해 자세히 알아보겠습니다. 머신러닝(Machine Learning) 전반전 - 인코딩(Encoding) 실습을 통해 데이터를 더욱 효과적으로 이해하고 활용하는 방법을 탐색해 보겠습니다.
데이터 인코딩에 대한 자세한 내용은 아래 글을 참고하시길 바라겠습니다.
머신러닝(Machine Learning) 데이터 인코딩(Encoding) 기초 (tistory.com)
머신러닝(Machine Learning) 데이터 인코딩(Encoding) 기초
서론 머신러닝은 컴퓨터가 스스로 학습하여 문제를 해결하는 연구 분야로, 이를 위해선 데이터가 필수적입니다. 이 데이터는 다양한 형태와 형식으로 존재하며, 이를 컴퓨터가 이해할 수 있는
10yp.tistory.com
원-핫 인코딩(One-Hot Encoding)
원-핫 인코딩은 Pandas와 사이킷런 라이브러리를 이용하여 사용할 수 있습니다. 각각의 방법에 대해 알아보도록 하겠습니다.
Pandas를 이용한 코드
import pandas as pd
one_hot = pd.get_dummies(df) #df의 모든 열을 원-핫 인코딩 진행
print(one_hot)
one_hot = pd.get_dummies(df, columns=['column_name1', 'column_name2',...]) #df의 특정 열을 원-핫 인코딩 진행
print(one_hot)

사이킷런(Sklearn)을 이용한 코드
from sklearn.preprocessing import OneHotEncoder
onehot_encoder = OneHotEncoder(sparse=False)
one_hot = onehot_encoder.fit_transform(df[["Sex","Embarked"]])
one_hot_df = pd.DataFrame(one_hot, columns=onehot_encoder.get_feature_names_out(["Sex", "Embarked"]))
df = pd.concat([df, one_hot_df], axis=1)
df.drop(columns=["Sex","Embarked"])
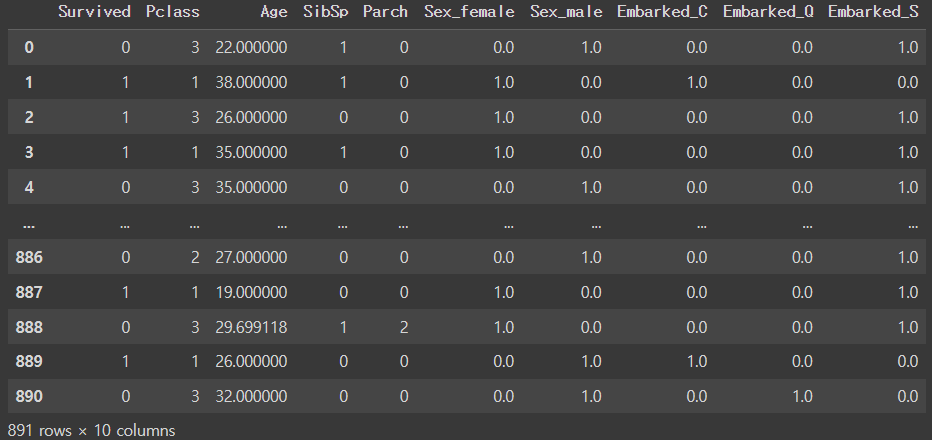
pandas를 이용할 경우 간단한 원-핫 인코딩이 가능합니다. 하지만, sklearn의 경우에는 다소 복잡하기 때문에 차근히 알아보겠습니다.
1.
onehot_encoder = OneHotEncoder(sparse=False): OneHotEncoder 객체를 생성합니다. 이때, sparse 인자를 False로 설정하면, 인코딩 후에 반환되는 배열이 희소 행렬(sparse matrix)가 아닌 밀집 배열(dense array) 형태가 됩니다. 희소 행렬(sparse matrix)과 밀집 배열(dense array)은 데이터의 값이 0인지 아닌지에 따라 이들을 효과적으로 저장하고 처리하는 방법을 의미합니다.
희소 행렬(sparse matrix)은 대부분의 값이 0으로 이루어진 행렬을 의미합니다. 이런 행렬에서는 0이 아닌 값만을 저장하는 방식을 사용해 메모리를 효율적으로 사용할 수 있습니다. 예를 들어, 원-핫 인코딩을 통해 변환된 데이터는 대부분의 값이 0이므로 희소 행렬로 표현하는 것이 효율적일 수 있습니다.
밀집 배열(dense array)은 대부분의 값이 0이 아닌 실수값을 가진 행렬을 의미합니다. 이런 행렬에서는 모든 값을 저장해야 하므로 희소 행렬에 비해 더 많은 메모리를 차지하게 됩니다. 원-핫 인코딩처럼 대부분의 값이 0인 데이터를 희소 행렬로 표현하면 메모리를 절약할 수 있지만, 희소 행렬을 다루는 연산은 밀집 배열을 다루는 연산에 비해 복잡하고 느릴 수 있습니다. 따라서 희소성과 연산의 복잡도 사이에서 적절한 균형을 찾는 것이 중요합니다.
2.
one_hot = onehot_encoder.fit_transform(df[["Sex","Embarked"]])
: OneHotEncoder 객체의 fit_transform 메소드를 사용하여 데이터에 원-핫 인코딩을 적용하고, 결과를 one_hot 변수에 저장합니다. fit_transform 메소드는 먼저 데이터에 대한 학습(fit)을 수행한 후, 해당 학습 결과로 변환(transform)을 수행하는 메소드입니다. 여기서 학습이란, 데이터의 각 범주에 대한 정보를 학습하는 것을 말합니다. 각 행은 원본 데이터의 각 요소를, 각 열은 원본 데이터의 각 범주를 나타냅니다. 해당 범주에 속하면 1, 그렇지 않으면 0의 값을 부여합니다.
3.
one_hot_df = pd.DataFrame(one_hot, columns=onehot_encoder.get_feature_names_out(["Sex", "Embarked"]))원-핫 인코딩 된 데이터를 데이터 프레임 형태로 만들어줍니다. 이 때 get_feature_names_out은 인코딩 되는 열의 이름을 "[]안의 피처명_데이터명"으로 수정해줍니다.
이렇게 원-핫 인코딩을 통해 범주형 데이터를 컴퓨터가 이해할 수 있는 형태로 변환할 수 있습니다.
4.
df = pd.concat([df, one_hot_df], axis=1)
df.drop(columns=["Sex","Embarked"])
df 데이터에 원핫인코딩 된 데이터 프레임을 연결하여주고, 인코딩 된 기존의 피처들을 삭제하여 줍니다.
Additional
만약 인코딩 하고자 하는 피처가 하나일 경우에는 위의 방법으로 진행 시 Series 데이터로 변형되기 때문에, 이를 2차원 배열로 변환하는 과정이 추가적으로 필요합니다.
▼ 인코딩 하려는 피처가 하나일 경우 예시 코드 ▼
# 'Sex' 열만 선택하려면 DataFrame에서 이를 선택하고 2D 배열로 변환해야 합니다.
feature = df[['Embarked']]
# 이제 OneHotEncoder를 초기화하고 'Embarked' 열에 적용하겠습니다.
encoder = OneHotEncoder(sparse=False)
one_hot = encoder.fit_transform(feature)
# 원-핫 인코딩된 데이터를 데이터프레임으로 변환합니다.
one_hot_df = pd.DataFrame(one_hot, columns=encoder.get_feature_names_out(['Embarked']))
# 원-핫 인코딩된 데이터프레임을 원래의 train 데이터프레임과 병합합니다.
df = pd.concat([df, one_hot_df], axis=1)
# 마지막으로 'Embarked' 열을 삭제합니다.
df = df.drop('Embarked', axis=1)
기타 사이킷런에 대한 설명은 해당 글을 참고해주시길 바랍니다.
머신러닝(Machine Learning) 알고리즘 라이브러리, 싸이킷런(scikit-learn) (tistory.com)
머신러닝(Machine Learning) 알고리즘 라이브러리, 싸이킷런(scikit-learn)
사이킷런 홈페이지: https://scikit-learn.org/stable/ scikit-learn: machine learning in Python — scikit-learn 1.3.2 documentation Model selection Comparing, validating and choosing parameters and models. Applications: Improved accuracy via paramete
10yp.tistory.com
결론
머신러닝(Machine Learning) 전반전 - 인코딩(Encoding) 실습을 진행해보았습니다. 기본적으로는 pandas의 OneHotEncoder를 사용하는 것이 간단하지만, sklearn의 OneHotEncoder를 사용하는 것이 유리한 경우들이 있습니다. 그 이유는 다음과 같습니다.
먼저, sklearn의 OneHotEncoder는 fit 메소드를 통해 데이터의 범주를 학습하고, 이를 다른 데이터에도 적용할 수 있습니다. 예를 들어, 학습 데이터에는 없지만 테스트 데이터에만 있는 범주가 있다면, pandas의 get_dummies 메소드를 사용하면 에러가 발생하거나 학습 데이터와 다른 구조의 데이터프레임이 생성될 수 있습니다. 이런 상황에서는 OneHotEncoder를 사용하여 학습 데이터의 범주를 학습하고, 이를 테스트 데이터에도 적용하는 것이 더 안전하고 일관성 있게 처리할 수 있습니다.
두번째로는, OneHotEncoder는 희소 행렬을 반환하는 옵션을 제공합니다. 이는 원-핫 인코딩 후 데이터의 차원이 크게 증가하는 문제를 완화하는데 도움이 됩니다. pandas의 get_dummies 메소드는 항상 밀집 배열 형태의 데이터프레임을 반환하므로, 이런 경우에는 메모리 사용량이 크게 증가할 수 있습니다.
세번째로 OneHotEncoder는 숫자형 범주도 변환할 수 있습니다. 반면, pandas의 get_dummies 메소드는 숫자형 범주를 그대로 두므로 이런 경우에는 OneHotEncoder를 사용하는 것이 더 유리할 수 있습니다. 따라서, 데이터의 특성과 처리해야 할 상황에 따라 pandas의 get_dummies 메소드와 sklearn의 OneHotEncoder 중 적절한 방법을 선택하는 것이 중요합니다.
데이터에 따라 다양한 인코딩 방법이 있기 때문에 그 상황에 맞게 적절한 인코더를 사용할 필요가 있겠습니다. 인코딩은 그 데이터를 컴퓨터가 활용할 수 있도록 만들어주는 과정입니다. 때문에, 데이터에 따라 필수적인 경우가 있습니다.
'데이터 사이언스 > 머신러닝 실습 전반전' 카테고리의 다른 글
| 머신러닝(Machine Learning) 실전 데이터 전처리 (74) | 2023.12.29 |
|---|---|
| 머신러닝(Machine Learning) 실전 탐색적 데이터 분석(EDA) (5) | 2023.12.27 |
| 머신러닝(Machine Learning) 전반전 - 데이터 스케일링 실습 (49) | 2023.12.08 |
| 머신러닝(Machine Learning) 전반전 - 데이터 전처리 실습 (42) | 2023.12.04 |
| 머신러닝(Machine Learning) 전반전 - 탐색적 데이터 분석(EDA) 실습 (58) | 2023.12.03 |