


"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
서론
데이터 분석의 세계에서, 이론과 실습은 중요한 기초를 마련해주지만, 실전에서의 데이터 처리는 그 자체로 별도의 도전이 될 수 있습니다. 데이터는 '실제 세계'의 복잡성을 반영하기 때문에, 이론적인 배경 지식만으로는 충분하지 않을 때가 많습니다. 이런 상황에서는 탐색적 데이터 분석(EDA)이 매우 유용한 도구가 될 수 있습니다.
머신러닝(Machine Learning) 실전 탐색적 데이터 분석(EDA) 글에서는 이전에 배운 EDA의 기본적인 개념과 실습을 바탕으로, 실전에서의 데이터 분석에 직면할 때 어떻게 EDA를 활용할 수 있는지에 대해 알아보겠습니다. 복잡하고 어려운 현실 세계의 데이터에 직면했을 때, 우리는 어떻게 아이디어를 찾아내고, 어떤 방향으로 분석을 진행해야 하는지에 대한 통찰을 얻을 수 있을 것입니다. 이를 위해 Python의 pandas, matplotlib, seaborn 라이브러리를 활용한 실전 EDA 기법에 초점을 맞추어 설명하겠습니다.
EDA(Exploratory Data Analysis, 탐색적 데이터 분석)
는 데이터를 파악하는 데 필요한 여러가지 방법들을 포함하고 있습니다. Python에서는 주로 pandas, matplotlib, seaborn 등의 라이브러리를 활용합니다. 여기서는 pandas와 matplotlib, seaborn을 사용한 EDA 코드에 대해 설명드리겠습니다.
1. 데이터 불러오기와 확인
: pandas 라이브러리를 사용하여 데이터를 불러오고, 기본적인 정보를 확인할 수 있습니다.
import pandas as pd
df = pd.read_csv('file.csv') # CSV 파일 불러오기
df.head() # 처음 5행 보기
df.tail() # 마지막 5행 보기
2. 데이터 정보 확인
: 데이터의 크기, 열의 이름, 각 열의 데이터 타입 등을 확인할 수 있습니다.
df.shape # 데이터의 행과 열의 수 확인
df.columns # 열 이름 확인
df.info() # 각 열의 데이터 타입과 null이 아닌 값의 수 확인
df.describe() # 수치형 열의 기술통계량 확인 (평균, 표준편차, 최소값, 중앙값, 최대값 등)
3. 결측치 확인
: 데이터에 결측치가 있는지 확인할 수 있습니다.
df.isnull().sum() # 각 열의 결측치 개수 확인
4. 데이터 분포 확인
: matplotlib 또는 seaborn을 사용하여 데이터의 분포를 시각화할 수 있습니다.
import matplotlib.pyplot as plt
import seaborn as snsplt.hist(df['column_name']) # 히스토그램으로 분포 확인
sns.boxplot(x='column_name', data=df) # 박스플롯으로 분포 확인
5. 상관관계 확인
: 두 변수간의 상관관계를 확인할 수 있습니다.
df.corr() # 변수간의 상관계수 확인
sns.heatmap(df.corr()) # 히트맵으로 상관계수 시각화
6. 범주형 데이터 확인
: 범주형 데이터의 각 범주별 개수를 확인할 수 있습니다.
df['column_name'].value_counts() # 각 범주의 개수 확인
sns.countplot(x='column_name', data=df) # 각 범주의 개수를 막대그래프로 시각화
7. 데이터 그룹화
: 특정 열을 기준으로 데이터를 그룹화하고, 그룹별 통계량을 계산할 수 있습니다.
df.groupby('column_name').mean() # 특정 열을 기준으로 그룹화하고, 그룹별 평균 계산
위와 같은 코드들을 통해 EDA를 수행하고, 데이터에 대한 통찰을 얻을 수 있습니다. 이와 같이 EDA는 데이터를 이해하는 데 큰 도움을 주며, 이후 데이터 전처리 및 모델링 방향을 결정하는 데 필요한 중요한 단계입니다.
예시1
탐색적 데이터 분석(EDA)의 필요성과 활용 예시를 설명하기 위해 캐글(Kaggle)에서 제공하는 '타이타닉 생존자' 데이터셋을 사용하겠습니다. 이 데이터셋은 타이타닉호의 승객 정보와 생존 여부가 담겨 있어, 데이터 분석의 기본적인 과정을 쉽게 이해할 수 있게 해줍니다. 먼저, pandas 라이브러리를 사용하여 데이터를 불러옵니다:
import pandas as pd
df = pd.read_csv('titanic.csv')
데이터를 불러온 후에는 가장 먼저 데이터의 기본적인 정보를 확인합니다.
df.info()
이를 통해 각 열의 데이터 타입과 null이 아닌 값의 수를 확인할 수 있습니다. 예를 들어, 'Age' 열에는 결측치가 많이 있음을 알 수 있습니다. 이는 이후 데이터 전처리 단계에서 결측치를 어떻게 처리할지 결정하는 데 도움이 됩니다.
다음으로, seaborn 라이브러리를 사용하여 '성별(Sex)'과 '생존(Survived)' 간의 관계를 시각화해봅니다.
import seaborn as sns
sns.countplot(x='Sex', hue='Survived', data=df)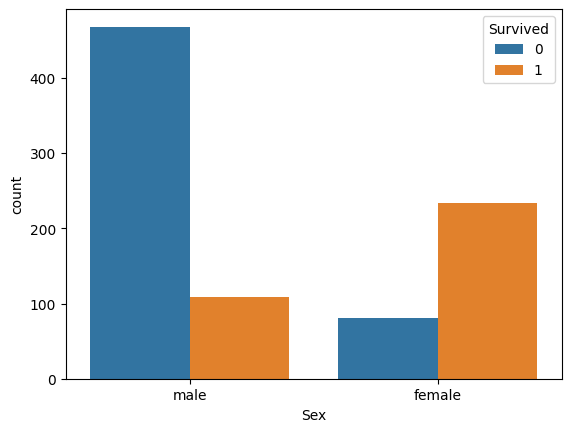
이를 통해 여성 승객이 남성 승객에 비해 생존 확률이 훨씬 높았음을 알 수 있습니다. 이러한 정보는 '성별'이 생존 여부를 예측하는 데 중요한 변수일 수 있음을 알려줍니다.
마지막으로, pandas의 `groupby` 함수를 사용하여 'Pclass(티켓 클래스)'와 'Survived' 간의 관계를 확인해봅니다.
python df.groupby('Pclass')['Survived'].mean()
이를 통해 1등급 티켓을 가진 승객이 생존 확률이 가장 높았음을 알 수 있습니다. 이는 'Pclass' 역시 생존 여부를 예측하는 데 중요한 변수일 수 있음을 알려줍니다. 이처럼 EDA는 데이터에 숨겨진 패턴을 찾아내고, 그 패턴이 결과에 어떤 영향을 미치는지 이해하는 데 도움을 줍니다. 이를 바탕으로 데이터 전처리 방향을 설정하거나, 모델링을 할 때 어떤 변수를 사용할지 결정할 수 있습니다. 따라서 EDA는 데이터 분석 과정에서 매우 중요한 단계입니다.
예시2
이번에는 캐글에서 제공하는 'Boston Housing Dataset'을 이용해 EDA의 필요성과 활용 예시를 설명하겠습니다. 이 데이터셋은 보스턴 지역의 주택 가격과 관련된 정보를 담고 있습니다.
우선, pandas 라이브러리를 사용하여 데이터를 불러옵니다.
import pandas as pd
df = pd.read_csv('boston_housing.csv')
데이터를 불러온 후에는 가장 먼저 데이터의 기본적인 정보를 확인합니다.
python df.info()
이를 통해 각 열의 데이터 타입과 null이 아닌 값의 수를 확인할 수 있습니다. 이를 통해 각 열에 결측치가 없음을 확인할 수 있습니다.
matplotlib를 사용하여 'RM(방의 개수)'과 'MEDV(중간 주택 가격)'의 관계를 시각화해봅니다.
import matplotlib.pyplot as plt
plt.scatter(df['RM'], df['MEDV'])
plt.xlabel('Number of Rooms')
plt.ylabel('Median House Price')
plt.title('Relation between RM and MEDV')
plt.show()
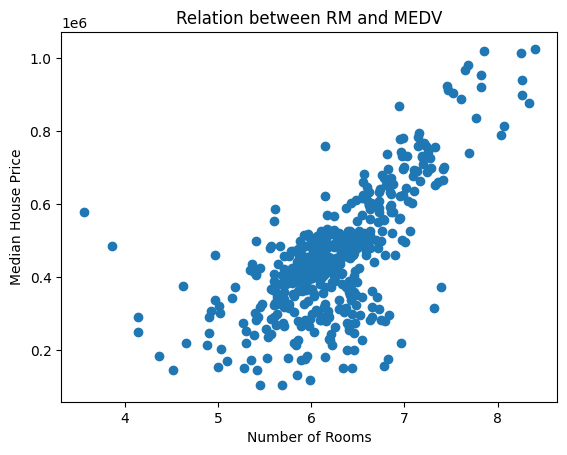
이를 통해 방의 개수가 많을수록 주택 가격이 상승하는 경향을 확인할 수 있습니다. 이 정보는 'RM'이 주택 가격을 예측하는데 중요한 변수일 수 있음을 알려줍니다.
마지막으로, seaborn 라이브러리를 사용하여 모든 변수들 간의 상관관계를 확인합니다.
import seaborn as sns
plt.figure(figsize=(10,10))
sns.heatmap(df.corr(), annot=True, cmap='coolwarm')
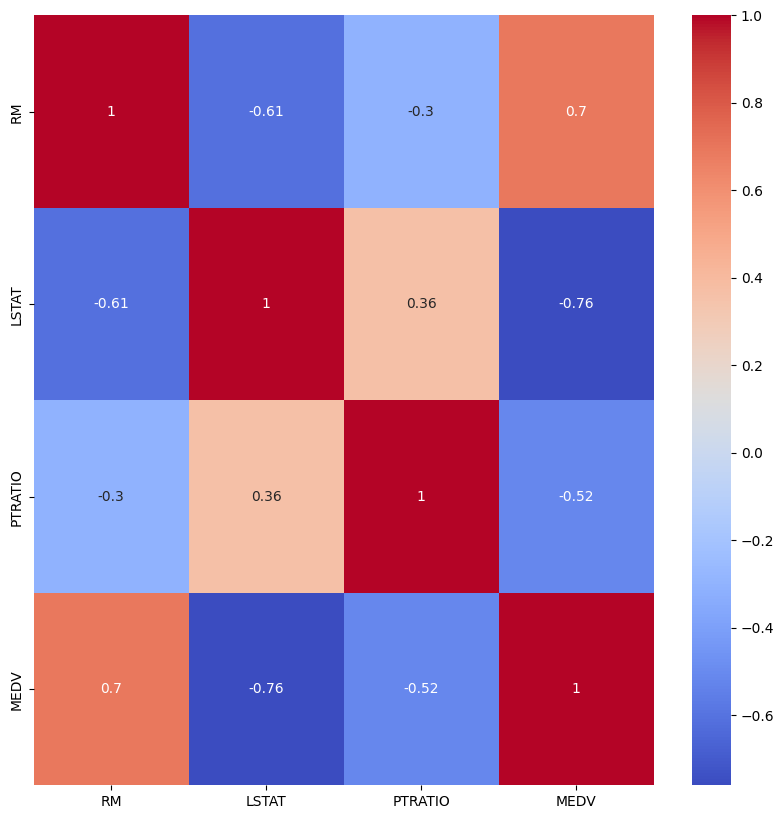
이를 통해 각 변수들 간의 상관관계를 한 눈에 확인할 수 있습니다. 이 정보는 변수 선택이나 다중 공선성 문제를 해결하는데 도움이 됩니다. 이처럼 EDA는 데이터를 이해하고, 분석 방향을 설정하는 데 중요한 도구입니다. 이를 통해 데이터에 숨겨진 패턴을 찾아내고, 이후 모델링 단계에서 어떤 변수를 사용할지 결정할 수 있습니다.
결론
탐색적 데이터 분석(EDA)는 데이터 분석의 첫 단계로, 데이터를 깊게 이해하는 데 중요한 역할을 합니다. 이번 분석에서 사용한 'Boston Housing Dataset'은 캐글에서 제공하는 보스턴 지역의 주택 가격과 관련된 데이터셋입니다. 우리는 데이터의 기본적인 정보를 확인하고, 변수들 간의 관계를 시각화하는 등의 방법으로 데이터를 탐색하였습니다. 이 과정에서 'RM(방의 개수)'이 'MEDV(중간 주택 가격)'에 큰 영향을 미치는 것을 확인할 수 있었습니다. 또한, 모든 변수들 간의 상관관계를 한 눈에 볼 수 있는 heatmap을 통해 변수 선택이나 다중 공선성 문제를 해결하는 데 도움이 되었습니다.
이처럼 EDA는 데이터에 숨겨진 패턴을 찾아내고, 이후 모델링 단계에서 어떤 변수를 사용할지 결정하는 데 중요한 도구입니다. 또한, 데이터의 노이즈나 이상치, 결측치 등을 발견하고 이를 적절히 처리하는 데도 중요한 역할을 합니다. 결론적으로, EDA는 데이터 분석의 성공을 위해 반드시 거쳐야 하는 과정으로, 분석자가 데이터를 잘 이해하고 이를 바탕으로 효과적인 모델을 만들어내는 데 큰 도움을 줍니다. 이번 분석을 통해 EDA의 중요성을 다시 한번 확인할 수 있었습니다. 이 분석이 EDA에 대해 공부하는 분들에게 조금이나마 도움이 되었기를 바랍니다.
'데이터 사이언스 > 머신러닝 실습 전반전' 카테고리의 다른 글
| 머신러닝(Machine Learning) 실전 데이터 인코딩(Data Encoding) (77) | 2023.12.29 |
|---|---|
| 머신러닝(Machine Learning) 실전 데이터 전처리 (74) | 2023.12.29 |
| 머신러닝(Machine Learning) 전반전 - 데이터 스케일링 실습 (49) | 2023.12.08 |
| 머신러닝(Machine Learning) 전반전 - 인코딩(Encoding) 실습 (57) | 2023.12.06 |
| 머신러닝(Machine Learning) 전반전 - 데이터 전처리 실습 (42) | 2023.12.04 |