


"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
서론
데이터를 접하다보면, 피처가 많은 경우가 있습니다. 너무 많은 피처를 어떻게 선택할 것인지, 그리고 어떻게 다룰 것인지에 대해 알아보겠습니다.
예시로 캐글의 대회 중 House Prices - Advanced Regression Techniques 데이터를 활용하겠습니다.
https://www.kaggle.com/competitions/house-prices-advanced-regression-techniques
House Prices - Advanced Regression Techniques | Kaggle
www.kaggle.com
1. 데이터 파악하기
데이터 프레임을 train로 지정하였습니다.
train = pd.read_csv('train 데이터 경로/train.csv')
train.shape()
해당 코드를 통해 데이터 프레임의 행, 열 갯수를 알 수 있습니다.
train.info()
해당 코드를 통해 각 피처별 데이터 갯수, 데이터 타입을 알 수 있습니다.
피처의 갯수가 많은 것을 알게 되었습니다. 더군다나, object, int64, float64 타입이 혼재되어 있습니다. 이런 경우에는 우선 타겟 데이터의 분포를 확인하는 것도 방법입니다.
이 데이터에서는 SalePrice를 예측하는 Competition이므로, SalePrice의 분포를 우선 살펴보겠습니다.
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
ax = sns.distplot(train['SalePrice'])
ax.set(ylabel="Frequency")
ax.set(xlabel="SalePrice")
ax.set(title="SalePrice distribution")
plt.show()
Target 데이터의 왜도와 첨도를 알아보겠습니다.
# Skew and kurt
print("Skewness: %f" % train['SalePrice'].skew())
print("Kurtosis: %f" % train['SalePrice'].kurt())
"왜도(Skewness)"와 "첨도(Kurtosis)"는 데이터의 분포 형태를 설명하는 통계학적 개념입니다.
1. 왜도(Skewness): 데이터의 비대칭도를 나타내는 지표입니다. 왜도값이 0이면 데이터의 분포가 정규 분포를 따르며, 왼쪽으로 치우친 경우 왜도값이 0보다 크고, 오른쪽으로 치우친 경우 왜도값이 0보다 작습니다.
주어진 데이터의 왜도값은 1.882876으로, 이는 데이터가 왼쪽으로 약간 치우쳐져 있음을 나타냅니다.
2. 첨도(Kurtosis): 데이터의 뾰족함을 나타내는 지표입니다. 첨도값이 0이면 데이터의 분포가 정규 분포를 따르며, 첨도값이 0보다 크면 정규 분포보다 뾰족한 분포(즉, 이상치가 더 많은 분포)를 나타내고, 첨도값이 0보다 작으면 정규 분포보다 완만한 분포(즉, 이상치가 더 적은 분포)를 나타냅니다.
주어진 데이터의 첨도값은 6.536282로, 이는 정규 분포보다 뾰족한 분포를 가지고 있음을 나타냅니다. 이 두 가지 지표를 통해 데이터의 분포 형태를 이해하는 데 도움이 됩니다.
타겟의 분포를 알아보았습니다. 그렇다면, 이번에는 수치형 데이터들과 타겟의 관계를 알아보도록 하겠습니다.
numeric_dtypes = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
numeric = []
for i in train.columns:
if train[i].dtype in numeric_dtypes:
if i in ['TotalSF', 'Total_Bathrooms','Total_porch_sf','haspool','hasgarage','hasbsmt','hasfireplace']:
pass
else:
numeric.append(i)
for i, feature in enumerate(list(train[numeric]), 1):
if(feature=='MiscVal'):
break
sns.scatterplot(x=feature, y='SalePrice', data=train)
plt.show()
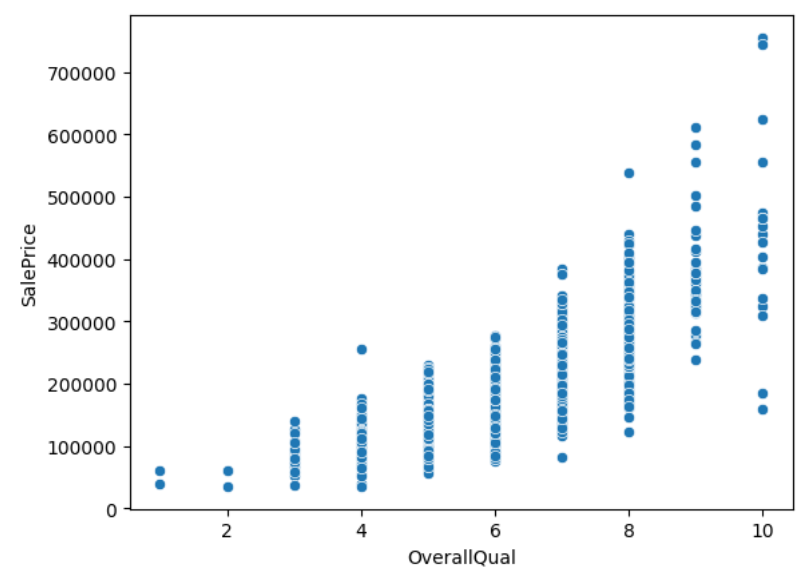
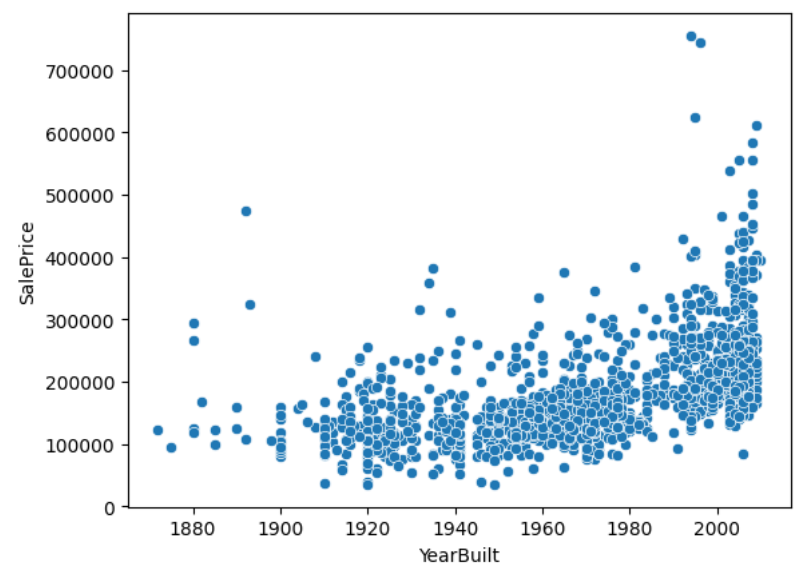
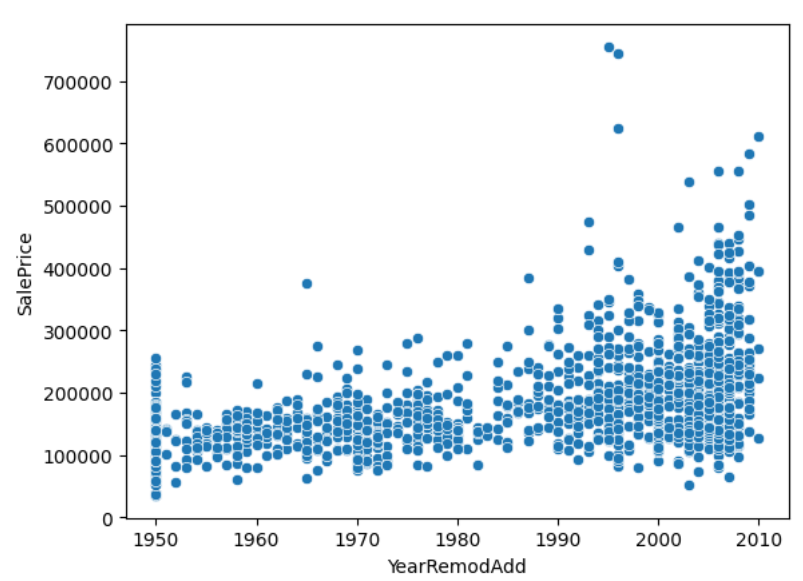
수많은 피처들의 각 경향성이 나타납니다. 여기서 우리가 주로 주목할 것은 x축의 증가에 따라 y축에 영향을 주는 피처들입니다. 즉, 유효한 영향을 주는 인자들을 한눈에 볼 수 있습니다.
결론
많은 피처가 있는 데이터를 처음 접하게 되면 어디서부터 시작할지 막막합니다. 이번 글에서 살펴본 것처럼 데이터의 전체적인 틀을 보고, 선택과 집중을 할 필요가 있습니다. 이후에는 적절한 피처를 찾아서 유효한 피처들을 좀 더 면밀히 분석하고, 학습시키는 과정을 통해 머신러닝을 진행할 수 있습니다.
이후에는 피처 엔지니어링 등 작업을 통해 접근하는 방법에 대해 다뤄보도록 하겠습니다.
블로그 인기글
KTX 코레일톡 자리 없을 때 취소표 쉽게 예매하는 꿀팁!!!
연말이 다가오면서, 사람들의 발걸음은 각자의 소중한 사람들을 만나러 떠나는 여정으로 이어집니다. 이런 중요한 순간, 기차 예매는 불가피하게 어려워질 수 있습니다. 하지만 걱정하지 마세요. KTX 코레일톡 어플리케이션의 간편 구매 기능!! 이 기능을 이용해서 여러분의 여행을 보다 편리하게 도와드릴 것입니다. 😊 본 글에서는 KTX 코레일톡 자리 없을 때 취소표 쉽게 예매하는 꿀팁(Tips)을 전해드립니다. KTX 코레일톡 어플리케이션의 간편 구매 기능을 소개하며, 이를 통해 기차 예매를 더욱 쉽고 편리하게 할 수 있는 방법에 대해 알아보겠습니다. 이 기능을 활용하면, 복잡한 과정 없이 몇 번의 클릭만으로 원하는 시간과 장소로의 기차 표를 예매할 수 있습니다. 이번 연말, KTX 코레일톡 어플리케이션과 함..
10yp.tistory.com
FT-IR의 원리와 활용
서론 적외선 분광법은 화학 분석 분야에서 필수적인 도구로 자리 잡았습니다. 특히, Fourier Transform Infrared Spectroscopy(FT-IR)는 그 중에서도 뛰어난 해석력과 사용의 편리함으로 인해 다양한 산업에서 널리 활용되고 있습니다. 본문에서는 FT-IR의 기본 원리와 함께, 이 기술이 어떻게 다양한 측정 방식으로 확장되어 식품 포장 재질 분석 등에 적용될 수 있는지를 설명합니다. 이를 통해 FT-IR이 식품 산업에서 어떤 방식으로 기여할 수 있는지, 그리고 식품 포장지의 재질을 식별하고 분석하는 과정에서 이 기술이 어떻게 사용되는지에 대한 깊이 있는 이해를 제공합니다. FT-IR(Fourier Transform Infrared Spectroscopy)은 적외선 분광법의 일종으..
10yp.tistory.com
'데이터 사이언스 > Kaggle' 카테고리의 다른 글
| 피처가 많을 때 머신러닝 어떻게 하나요 - 3편(PCA) (4) | 2024.03.12 |
|---|---|
| 피처가 많을 때 머신러닝 어떻게 하나요 - 2편 (3) | 2024.03.05 |
| 붓꽃 품종 분류 문제 데이터 로드부터 해결까지 Iris clustering (79) | 2024.01.16 |
| 캐글 실전 자전거 공유 수요 예측 (4) | 2024.01.12 |
| 캐글 실전 titanic 생존자 예측 (5) | 2024.01.11 |