


"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
서론
이 글은 "캐글 실전 자전거 공유 수요 예측"에 대한 내용을 담고 있습니다. 데이터 분석의 중요성이 갈수록 높아지는 현재, 데이터의 통찰력을 바탕으로 실제 문제를 해결하는 능력은 매우 중요한 역량입니다. 이 글에서는 실제 캐글 경진대회에서 사용되었던 자전거 대여 수요 데이터를 활용하여 탐색적 데이터 분석과정부터 모델 학습, 검증, 그리고 예측까지의 전체 프로세스를 담고 있습니다. 데이터 전처리부터 시작하여, 변수들의 상관관계 분석, 시간대별/요일별/계절별 대여 패턴 분석, 그리고 기온, 습도, 풍속 등의 연속적인 특징들의 분포 확인 등 다양한 방법으로 데이터를 탐색합니다.
이후 데이터 인코딩, 스케일링을 통해 모델이 학습할 수 있는 형태로 데이터를 변환하고, RandomForestRegressor라는 머신러닝 모델을 사용하여 학습을 진행합니다. 모델 학습 후에는 검증 데이터를 통해 모델의 성능을 평가하고, 필요한 경우 하이퍼파라미터 튜닝을 통해 모델의 성능을 개선합니다. 마지막으로, 최적의 모델로 실제 테스트 데이터에 대한 수요를 예측하고 결과를 제출하는 과정까지를 다룹니다. 이렇게 전체 데이터 분석 프로세스를 캐글 경진대회 문제 해결을 통해 실습함으로써, 이론과 실제의 연결고리를 이해하고, 머신러닝 모델을 사용한 문제 해결 능력을 향상시킬 수 있습니다.
https://www.kaggle.com/competitions/bike-sharing-demand/data
Bike Sharing Demand | Kaggle
www.kaggle.com
1. 탐색적 데이터 분석
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
base_path = "/content/"
train = pd.read_csv(base_path + "train.csv")
test = pd.read_csv(base_path + "test.csv")train.info()
train.describe()
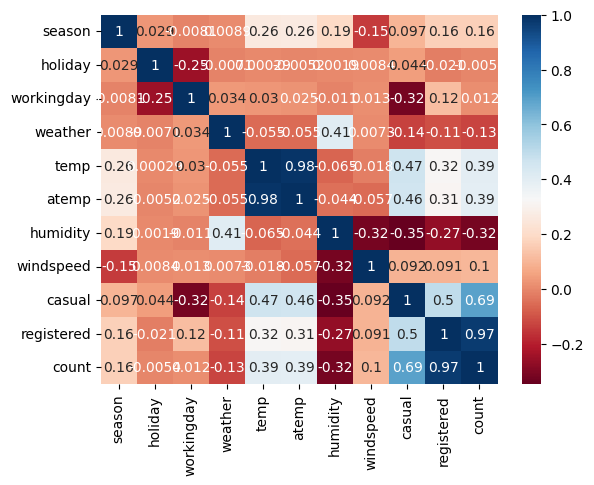
각 특징과 대여 수와의 상관관계 분석
#각 특징과 대여 수와의 상관관계 분석
import seaborn as sns
correlation_matrix = train.corr()
sns.heatmap(correlation_matrix, annot=True, cmap='RdBu')
시간대별, 요일별, 계절별 대여 패턴 분석
# datetime을 datetime 타입으로 변환하고, 시간과 요일을 추출
train['datetime'] = pd.to_datetime(train['datetime'])
train['hour'] = train['datetime'].dt.hour
train['dayofweek'] = train['datetime'].dt.dayofweek
# 시간대별 대여 횟수
sns.barplot(x='hour', y='count', data=train)
# 요일별 대여 횟수
sns.barplot(x='dayofweek', y='count', data=train)
# 계절별 대여 횟수
sns.barplot(x='season', y='count', data=train)



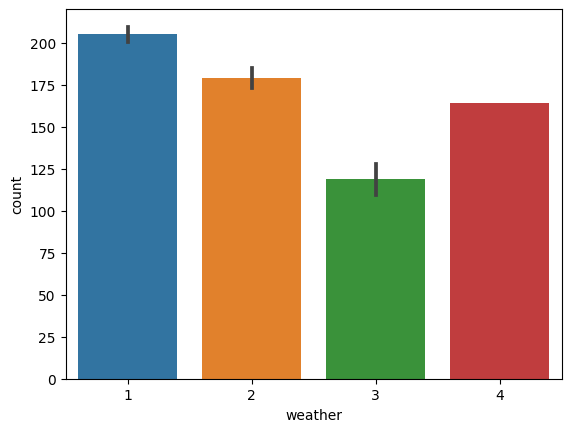
날씨 상태, 휴일, 근무일 등에 따른 대여 패턴 분석
# 날씨 상태별 대여 횟수
sns.barplot(x='weather', y='count', data=train)
# 휴일 여부별 대여 횟수
sns.barplot(x='holiday', y='count', data=train)
# 근무일 여부별 대여 횟수
sns.barplot(x='workingday', y='count', data=train)
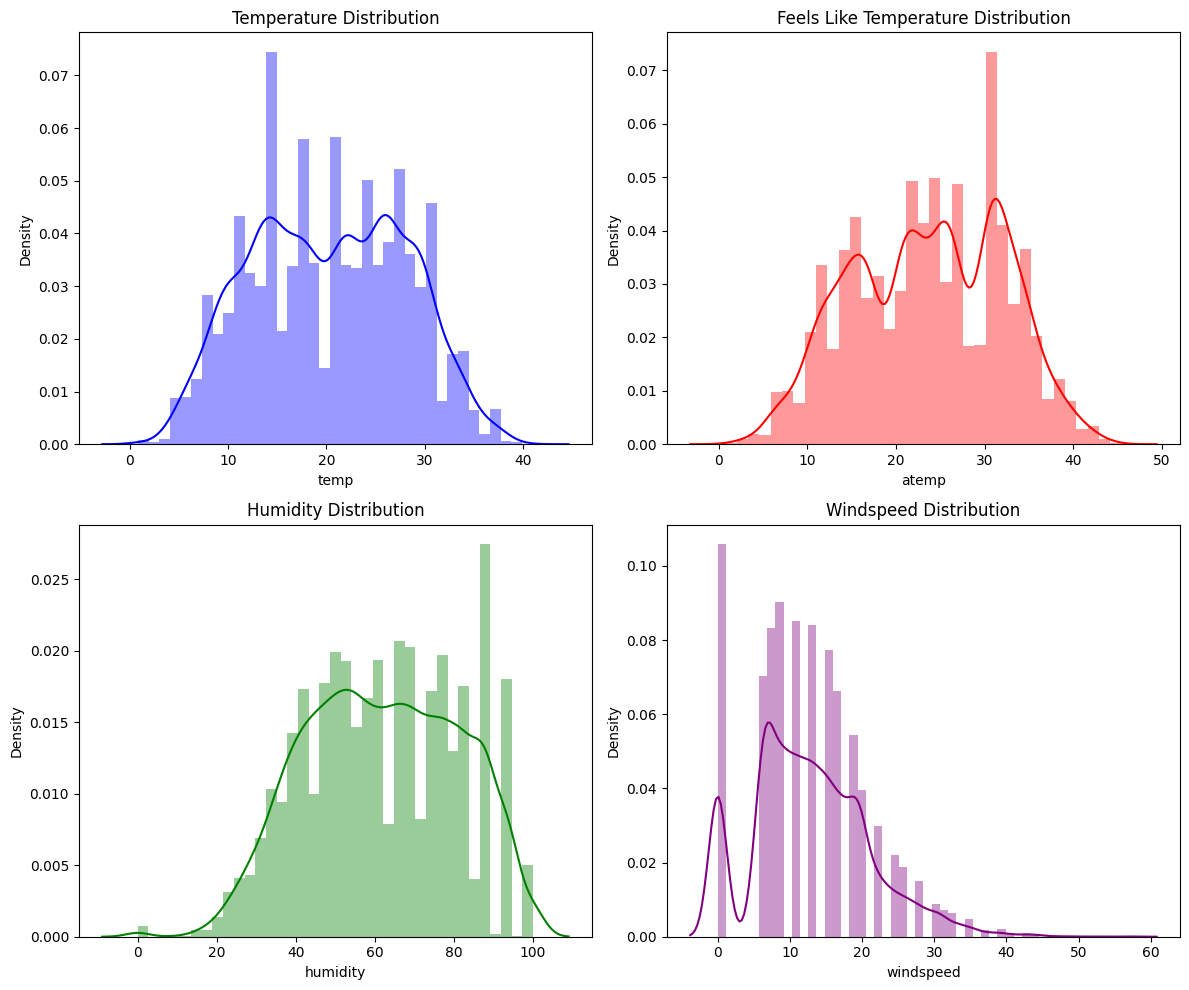
온도, 체감온도, 습도, 풍속 등의 연속적인 특징들의 분포 확인
import matplotlib.pyplot as plt
fig, axs = plt.subplots(2, 2, figsize=(12, 10))
sns.distplot(train['temp'], ax=axs[0, 0], color='blue')
axs[0, 0].set_title('Temperature Distribution')
sns.distplot(train['atemp'], ax=axs[0, 1], color='red')
axs[0, 1].set_title('Feels Like Temperature Distribution')
sns.distplot(train['humidity'], ax=axs[1, 0], color='green')
axs[1, 0].set_title('Humidity Distribution')
sns.distplot(train['windspeed'], ax=axs[1, 1], color='purple')
axs[1, 1].set_title('Windspeed Distribution')
plt.tight_layout()
plt.show()
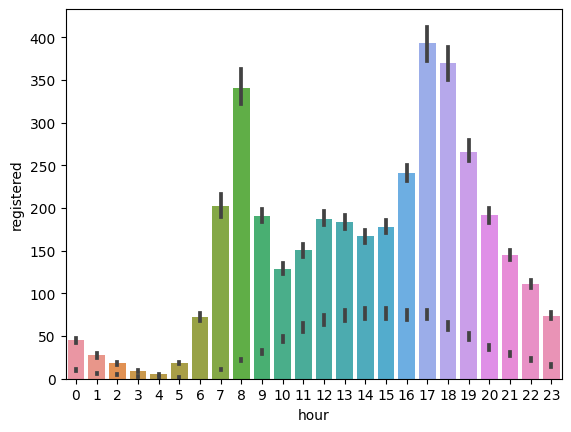
비회원과 회원의 대여 패턴 비교
# 비회원의 대여 횟수
sns.barplot(x='hour', y='casual', data=train)
# 회원의 대여 횟수
sns.barplot(x='hour', y='registered', data=train)
2. 데이터 전처리
# 불필요한 열 제거
train = train.drop(['casual', 'registered','datetime'], axis=1)
3. 데이터 인코딩
# 범주형 변수 처리
categorical_features = ['season', 'holiday', 'workingday', 'weather']
train = pd.get_dummies(train, columns=categorical_features)
4. 데이터 스케일링
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
continuous_features = ['temp', 'atemp', 'humidity', 'windspeed']
train[continuous_features] = scaler.fit_transform(train[continuous_features])
5. 데이터 스플릿
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_log_error
# 피처와 타깃 분리
X = train.drop('count', axis=1)
y = train['count']
# 학습/검증 데이터 분리
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
6. 모델 선택 및 학습
# 모델 생성 및 학습
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
7. 모델 검증 및 하이퍼파라미터 튜닝
# 검증 데이터를 사용한 예측 및 평가
y_pred = model.predict(X_val)
y_pred = np.clip(y_pred, 0, np.inf) # 예측값이 음수인 경우 0으로 처리
rmsle = np.sqrt(mean_squared_log_error(y_val, y_pred))
print('RMSLE: ', rmsle)
from sklearn.model_selection import GridSearchCV
# 하이퍼파라미터 그리드 정의
param_grid = {
'n_estimators': [100, 200, 300, 400, 500],
'max_depth': [None, 10, 20, 30, 40, 50],
}
# GridSearchCV 객체 생성
grid_search = GridSearchCV(model, param_grid, cv=5, scoring='neg_mean_squared_log_error', n_jobs=-1)
# 모델 학습
grid_search.fit(X, y)
# 최적의 하이퍼파라미터 출력
print('Best parameters: ', grid_search.best_params_)
# 최적의 하이퍼파라미터에 대한 성능 출력
print('Best RMSLE: ', np.sqrt(-grid_search.best_score_))
8. 성능 평가
from sklearn.metrics import mean_squared_log_error
# 테스트 세트에 대한 예측 수행
y_pred = grid_search.best_estimator_.predict(X_test)
# RMSLE 계산
rmsle = np.sqrt(mean_squared_log_error(y_test, y_pred))
print('Test RMSLE: ', rmsle)
테스트 데이터에 대해서도 동일한 절차로 수행합니다.
# 테스트 데이터 로드
test = pd.read_csv(base_path + "test.csv")
# datetime 타입으로 변환하고, 시간과 요일 추출
test['datetime'] = pd.to_datetime(test['datetime'])
test['hour'] = test['datetime'].dt.hour
test['dayofweek'] = test['datetime'].dt.dayofweek
# 불필요한 열 제거
test = test.drop(['datetime'], axis=1)
# 범주형 변수 처리
categorical_features = ['season', 'holiday', 'workingday', 'weather']
test = pd.get_dummies(test, columns=categorical_features)
# 데이터 스케일링
test[continuous_features] = scaler.transform(test[continuous_features])
# 테스트 데이터에 대한 예측 수행
test_pred = model.predict(test)
# 결과를 데이터프레임으로 변환
test_pred_df = pd.DataFrame(test_pred, columns=['count'])
# 'datetime' 열 불러오기
test_datetime = pd.read_csv(base_path + "test.csv", usecols=['datetime'])
# 결과 데이터프레임에 'datetime' 열 추가
test_pred_df = pd.concat([test_datetime, test_pred_df], axis=1)
# csv 파일로 저장
test_pred_df.to_csv(base_path + "submission.csv", index=False)
결론
"캐글 실전 자전거 공유 수요 예측"에서의 EDA(탐색적 데이터 분석) 결과는 각 단계에서 매우 중요한 역할을 하였습니다.
1. 탐색적 데이터 분석 및 데이터 전처리: EDA를 통해 데이터의 개요를 파악하고, null 값, 이상치, 불필요한 열 등을 확인하였습니다. 이를 바탕으로 데이터 전처리 단계에서 불필요한 열을 제거하거나, 데이터를 적절한 형태로 변환하는 등의 작업을 진행하였습니다.
2. 데이터 인코딩: EDA에서는 각 변수들의 분포와 대여 수와의 관계를 확인하였습니다. 이를 통해 범주형 변수들이 대여 수에 어떤 영향을 미치는지 파악하였고, 이를 바탕으로 데이터 인코딩에서는 범주형 변수들을 One-hot encoding 방식으로 변환하였습니다.
3. 데이터 스케일링: EDA에서 연속적인 특징들의 분포를 확인하였습니다. 이를 바탕으로 데이터 스케일링에서는 이러한 연속적인 특징들을 MinMaxScaler를 이용하여 0과 1 사이의 값으로 변환하였습니다.
4. 데이터 스플릿: EDA에서 각 특징과 대여 수와의 상관관계를 분석하였습니다. 이를 통해 모델 학습에 필요한 피처와 타깃을 결정하였고, 이를 바탕으로 데이터 스플릿 단계에서는 피처와 타깃을 분리하고, 학습 데이터와 검증 데이터를 분리하였습니다.
5. 모델 선택 및 학습: EDA에서 변수간의 관계와 대여 수와의 관계를 분석하였습니다. 이를 통해 RandomForestRegressor라는 결정 트리 기반의 모델이 적합할 것이라 판단하였고, 이를 바탕으로 모델 선택 및 학습 단계에서는 RandomForestRegressor 모델을 학습하였습니다.
6. 모델 검증 및 하이퍼파라미터 튜닝: EDA에서 얻은 인사이트를 바탕으로 모델의 성능을 평가하였고, 필요한 경우 하이퍼파라미터 튜닝을 통해 모델의 성능을 개선하였습니다.
7. 성능 평가: EDA를 통해 얻은 데이터의 특성과 모델의 특성을 고려하여 적절한 성능 지표를 선택하였습니다. 이를 바탕으로 최종적으로 모델의 성능을 평가하였습니다. 따라서, EDA는 데이터 전처리부터 모델의 성능 평가까지 각 단계에서 중요한 영향을 끼치며, 데이터의 특성을 이해하고, 효과적인 모델 학습을 위한 방향성을 제시하였습니다.
이 글에서는 "캐글 실전 자전거 공유 수요 예측"을 통해 데이터 분석의 전체적인 흐름과 머신러닝 모델의 적용 과정을 살펴보았습니다. 데이터 전처리부터 시작하여, 탐색적 데이터 분석, 인코딩, 스케일링, 모델 학습, 검증, 그리고 예측까지의 과정을 체계적으로 진행하였습니다. 특히, RandomForestRegressor라는 머신러닝 모델을 통해 학습을 진행하였고, 그 성능을 검증하였습니다. 더 나아가, GridSearchCV를 이용하여 최적의 하이퍼파라미터를 찾는 과정을 통해 모델의 성능을 개선하는 방법을 확인하였습니다.
마지막으로, 최적의 모델로 실제 테스트 데이터에 대한 수요를 예측하고, 그 결과를 제출하는 과정을 통해 실제 문제 해결에 어떻게 접근해야 하는지에 대한 방향성을 제시하였습니다. 이를 통해, 이론과 실제가 어떻게 연결되는지를 이해하였으며, 머신러닝 모델을 이용한 실제 문제 해결 능력을 향상시킬 수 있었습니다. 이러한 과정은 데이터 분석의 실용성과 중요성을 잘 보여주며, 앞으로 이 분야에 도전하려는 모든 분들에게 유용한 지침이 될 것입니다.
'데이터 사이언스 > Kaggle' 카테고리의 다른 글
| 피처가 많을 때 머신러닝 어떻게 하나요 - 3편(PCA) (4) | 2024.03.12 |
|---|---|
| 피처가 많을 때 머신러닝 어떻게 하나요 - 2편 (3) | 2024.03.05 |
| 피처가 많을 때 머신러닝 어떻게 하나요 - 1편 (73) | 2024.03.04 |
| 붓꽃 품종 분류 문제 데이터 로드부터 해결까지 Iris clustering (79) | 2024.01.16 |
| 캐글 실전 titanic 생존자 예측 (5) | 2024.01.11 |