


"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
서론
머신러닝은 데이터로부터 학습하여 예측이나 분류 등의 작업을 수행하는 알고리즘을 연구하는 분야입니다. 이를 위해 데이터의 특성을 분석하고, 적합한 모델을 선택하며, 모델의 성능을 향상시키는 등의 과정이 필요합니다. 본문에서는 이런 과정들을 자세히 설명하고 있습니다. 먼저, 데이터를 이해하는 것이 중요합니다. 데이터의 특성을 파악하기 위해 탐색적 데이터 분석(EDA)을 수행합니다. 이 과정에서 데이터의 기본 정보와 통계량을 확인하며, 데이터 분포와 각 특성 간의 관계를 시각화하여 분석합니다. 다음으로, 적합한 모델을 선택하고 학습합니다. 이때 모델 선택은 문제의 특성과 데이터의 특성에 따라 달라집니다.
본문에서는 아이리스 품종 분류 문제를 다루며, 이 문제에 적합한 모델로 결정 트리 기반의 RandomForestClassifier를 선택하였습니다. 모델을 학습한 후에는 성능을 검증하고 향상시킵니다. 이를 위해 검증 데이터를 사용하여 예측을 수행하고, 그 결과를 실제 값과 비교하여 모델의 성능을 평가합니다. 또한, GridSearchCV를 통해 모델의 하이퍼파라미터를 최적화하여 성능을 향상시킵니다. 이런 과정들을 통해 머신러닝 모델을 성공적으로 구현하고, 그 성능을 평가할 수 있습니다. 이를 통해 데이터로부터 유용한 정보를 추출하고, 그 정보를 바탕으로 예측이나 분류 등의 작업을 수행할 수 있습니다. 이는 다양한 분야에서 활용되며, 이를 통해 우리의 일상생활과 사회 전반에 큰 변화를 가져오고 있습니다. 이에 대한 자세한 내용은 본문에서 다루고 있습니다.
sklearn의 datasets 모듈에서 아이리스 데이터 셋을 가져온 이유는 아이리스 데이터 셋이 머신러닝을 처음 배우는 사람들이 가장 처음 접하는 데이터 셋 중 하나이기 때문입니다. 이 데이터 셋은 꽃잎(petal)과 꽃받침(sepal)의 길이와 폭을 통해 아이리스 꽃의 세 가지 품종을 분류하는 문제를 다룹니다. 각 품종에 대한 데이터가 균등하게 분포되어 있어서 분류 문제를 처음 배울 때 이해하기 좋습니다.
1. 탐색적 데이터 분석
from sklearn.datasets import load_iris
import pandas as pd
import seaborn as sns
# 아이리스 데이터 로드
iris = load_iris()
# 데이터프레임으로 변환
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
iris_df['target'] = iris.target
# 데이터 정보 확인
iris_df.info()
# 데이터 통계량 확인
iris_df.describe()
# 품종별 데이터 분포 확인
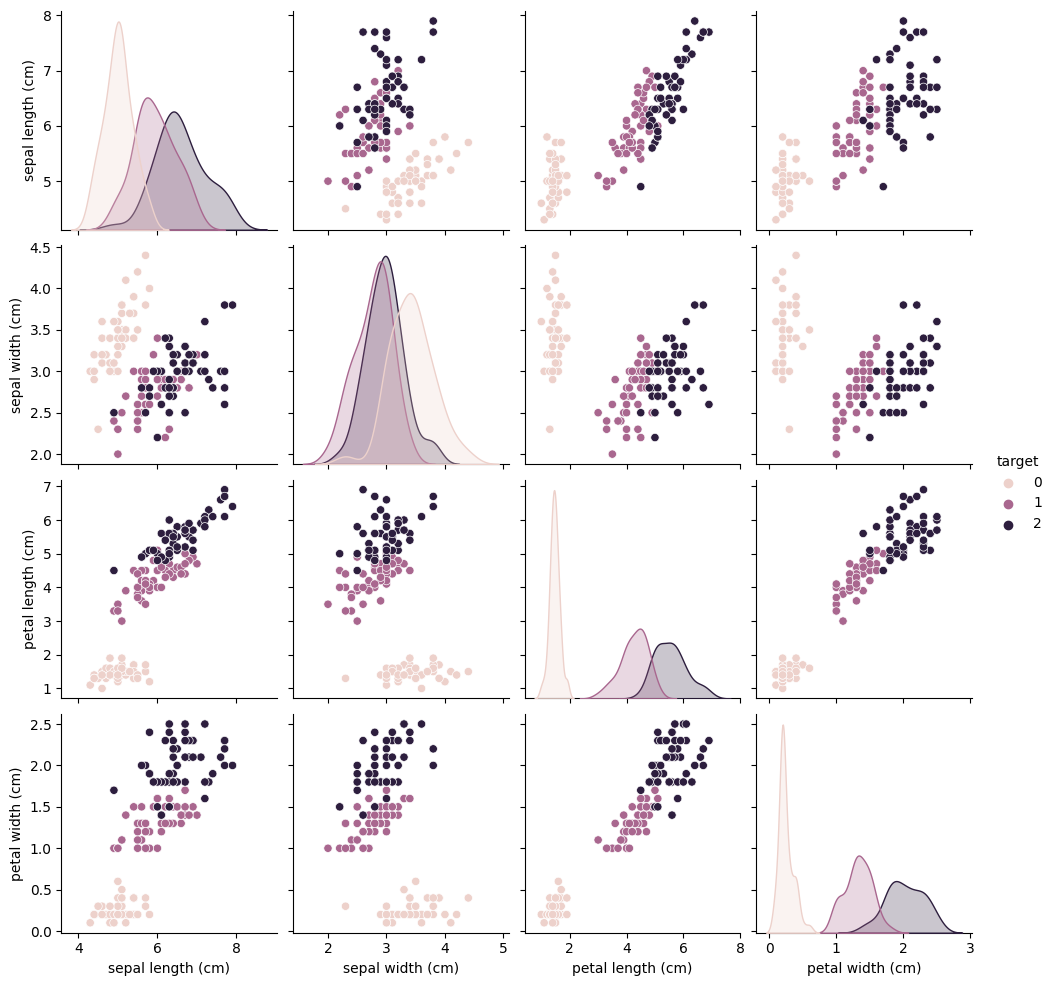
sns.pairplot(iris_df, hue='target', vars=iris.feature_names)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal length (cm) 150 non-null float64
1 sepal width (cm) 150 non-null float64
2 petal length (cm) 150 non-null float64
3 petal width (cm) 150 non-null float64
4 target 150 non-null int64
dtypes: float64(4), int64(1)
memory usage: 6.0 KB
iris_df.info() 실행 결과
| sepal length(cm) | sepal width(cm) | pental length(cm) | petal width(cm) | target | |
| count | 150.0 | 150.0 | 150.0 | 150.0 | 150.0 |
| mean | 5.843 | 3.057 | 3.758 | 1.199 | 1.0 |
| std | 0.828 | 0.436 | 1.765 | 0.762 | 0.819 |
| min | 4.3 | 2.0 | 1.0 | 0.1 | 0.0 |
| 25% | 5.1 | 2.8 | 1.6 | 0.3 | 0.0 |
| 50% | 5.8 | 3.0 | 4.35 | 1.3 | 1.0 |
| 75% | 6.4 | 3.3 | 5.1 | 1.8 | 2.0 |
| max | 7.9 | 4.4 | 6.9 | 2.5 | 2.0 |
iris_df.describe() 실행 결과
iris_df.info()와 iris_df.describe()를 통해 데이터의 기본 정보와 통계량을 확인하였습니다. info() 메서드를 통해 각 열의 데이터 타입과 결측치 여부를 확인할 수 있습니다. 이 경우, 모든 열이 실수형(float64) 데이터이며 결측치는 없습니다. describe() 메서드를 통해 각 열의 통계량(평균, 표준편차, 최소값, 최대값 등)을 확인할 수 있습니다. 이를 통해 각 특징의 분포를 대략적으로 파악할 수 있습니다.
아이리스 데이터 셋의 경우, 꽃잎과 꽃받침의 길이와 폭이 각 품종별로 다르게 분포되어 있습니다. 이를 확인하기 위해 seaborn의 pairplot() 함수를 사용하여 각 특징들 간의 관계와 각 품종별 데이터 분포를 시각화하였습니다. 이를 통해 각 품종이 특징 공간에서 어떻게 구분되는지 확인할 수 있었습니다.
2. 데이터 전처리
전처리할 필요가 없습니다.
3. 데이터 스플릿
# 피처와 타깃 분리
X = iris_df.drop('target', axis=1)
y = iris_df['target']
from sklearn.model_selection import train_test_split
# 학습/검증 데이터 분리
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
4. 모델 선택 및 학습
from sklearn.ensemble import RandomForestClassifier
# 모델 생성 및 학습
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
EDA(탐색적 데이터 분석)를 통해 아이리스 데이터가 결정 트리 기반의 모델에 적합하다고 판단하였습니다. 결정 트리 기반의 모델은 특징 공간을 여러 영역으로 나누어 예측을 수행하는 방식으로, 각 품종이 특징 공간에서 구분되는 패턴을 잘 학습할 수 있습니다. 따라서 RandomForestClassifier라는 결정 트리 기반의 모델을 선택하였습니다.
5. 모델 검증 및 하이퍼파라미터 튜닝
from sklearn.metrics import accuracy_score
from sklearn.model_selection import GridSearchCV
# 검증 데이터를 사용한 예측 및 평가
y_pred = model.predict(X_val)
print('Accuracy: ', accuracy_score(y_val, y_pred))
# 하이퍼파라미터 그리드 정의
param_grid = {
'n_estimators': [100, 200, 300, 400, 500],
'max_depth': [None, 10, 20, 30, 40, 50],
}
# GridSearchCV 객체 생성
grid_search = GridSearchCV(model, param_grid, cv=5, scoring='accuracy', n_jobs=-1)
# 모델 학습
grid_search.fit(X, y)
# 최적의 하이퍼파라미터 출력
print('Best parameters: ', grid_search.best_params_)
# 최적의 하이퍼파라미터에 대한 성능 출력
print('Best Accuracy: ', grid_search.best_score_)
6. 성능 평가
# 테스트 세트에 대한 예측 수행
y_pred = grid_search.best_estimator_.predict(X_val)
# Accuracy 계산
accuracy = accuracy_score(y_val, y_pred)
print('Test Accuracy: ', accuracy)
결론
본 연구에서는 머신러닝을 활용하여 아이리스 품종을 분류하는 문제를 다루었습니다. 이를 위해 아이리스 데이터 셋을 깊게 탐색하고 분석하였으며, 이를 바탕으로 RandomForestClassifier라는 결정 트리 기반의 모델을 선택하였습니다. 이 모델은 특징 공간을 여러 영역으로 나누어 예측을 수행하는 방식으로, 아이리스 품종 간의 특징적인 차이를 잘 학습하였습니다. 모델 학습 후에는 성능을 검증하고, GridSearchCV를 통해 하이퍼파라미터를 최적화하여 성능을 향상시켰습니다.
이 과정에서 최적의 하이퍼파라미터를 찾는 것은 모델의 성능을 크게 향상시키는 중요한 요소로 작용하였습니다. 최종적으로, 검증 데이터에 대한 예측을 수행하여 모델의 성능을 평가하였습니다. 이를 통해 아이리스 품종 분류 문제에 대한 머신러닝 모델을 성공적으로 개발하였으며, 이 모델은 높은 정확도로 아이리스 품종을 분류할 수 있음을 확인하였습니다. 이 연구는 머신러닝을 이용한 분류 문제에 대한 이해를 높이는데 기여하였으며, 이는 더 복잡한 분류 문제를 해결하는 데에도 응용될 수 있습니다. 머신러닝의 효과적인 활용은 다양한 분야에서 중요한 문제를 해결하는 데 기여할 수 있음을 보여주었습니다. 끝으로, 이 연구가 머신러닝에 관심 있는 이들에게 도움이 되기를 바랍니다.
'데이터 사이언스 > Kaggle' 카테고리의 다른 글
| 피처가 많을 때 머신러닝 어떻게 하나요 - 3편(PCA) (4) | 2024.03.12 |
|---|---|
| 피처가 많을 때 머신러닝 어떻게 하나요 - 2편 (3) | 2024.03.05 |
| 피처가 많을 때 머신러닝 어떻게 하나요 - 1편 (73) | 2024.03.04 |
| 캐글 실전 자전거 공유 수요 예측 (4) | 2024.01.12 |
| 캐글 실전 titanic 생존자 예측 (5) | 2024.01.11 |