


"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
지난 글
https://10yp.tistory.com/manage/newpost/142?type=post&returnURL=https%3A%2F%2F10yp.tistory.com%2F142
https://10yp.tistory.com/manage/newpost/142?returnURL=https%3A%2F%2F10yp.tistory.com%2F142&type=post
10yp.tistory.com
에서는 많은 피처들이 있는 것을 파악하고, 타겟의 데이터 분포 형태와 타겟과 피처간의 관계의 경향성을 파악하였습니다. 이렇게 파악한 정보를 바탕으로 세부적으로 피처를 선별하여서 타겟 예측에 활용할 수 있습니다. 이번에는 1차적으로 선별된 피처들을 바탕으로 타겟과의 관계를 파악해보겠습니다.
지난 글에서 타겟과 피처의 관계 분석을 위한 코드를 한눈에 보기 좋게 수정한 코드입니다.
numeric_dtypes = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
numeric = []
for i in train.columns:
if train[i].dtype in numeric_dtypes:
if i in ['TotalSF', 'Total_Bathrooms','Total_porch_sf','haspool','hasgarage','hasbsmt','hasfireplace']:
pass
else:
numeric.append(i)
# visualising some more outliers in the data values
fig, axs = plt.subplots(ncols=2, nrows=1, figsize=(12, 120))
plt.subplots_adjust(right=2)
plt.subplots_adjust(top=2)
sns.color_palette("husl", 8)
for i, feature in enumerate(list(train[numeric]), 1):
if(feature=='MiscVal'):
break
plt.subplot(len(list(numeric)), 3, i)
sns.scatterplot(x=feature, y='SalePrice', hue='SalePrice', palette='Blues', data=train)
plt.xlabel('{}'.format(feature), size=15,labelpad=12.5)
plt.ylabel('SalePrice', size=15, labelpad=12.5)
for j in range(2):
plt.tick_params(axis='x', labelsize=12)
plt.tick_params(axis='y', labelsize=12)
plt.legend(loc='best', prop={'size': 10})
plt.show()

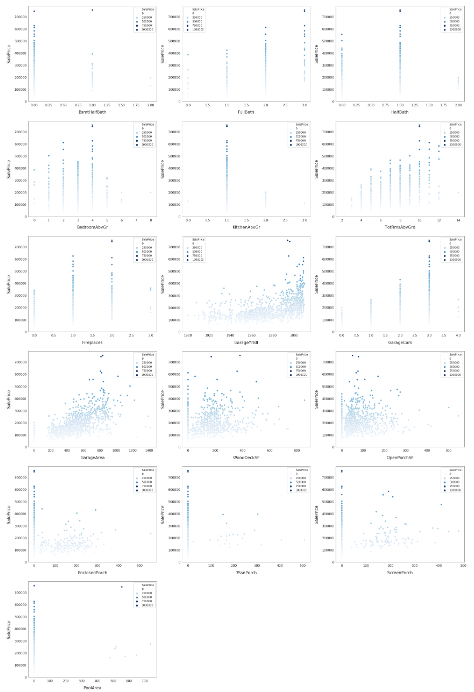
이 중 시각화를 바탕으로 유효하다고 판단되는 수치형 피처는
Overallqual
yearbuilt
yearremodadd
totalbsmlsf
1stFirSF
2ndFirSF
GrLivArea
FullBath
TotRmsAbvGrd
GarageYrBit
GarageCars
GarageArea
입니다. 이 중 몇가지를 시각화하여 세부적으로 데이터 분포를 확인해보고, 전처리하도록 하겠습니다.
우선 데이터에 결측치가 많은 피처는 과감하게 삭제하도록 하겠습니다. 데이터의 개수가 1460개이므로, 이의 20%를 기준으로 삼아보겠습니다.
missing_data = train.isnull().sum()
missing_data_cols = missing_data[missing_data > 1460*0.2].index
train = train.drop(missing_data_cols, axis=1)
다음은 경향성이 보인 OverallQual 피처에 대한 처리입니다.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
train = pd.read_csv("train 저장경로/train.csv")
data = pd.concat([train['SalePrice'], train['OverallQual']], axis=1)
sns.boxplot(x=train['OverallQual'], y="SalePrice", data=data)
plt.ylim(0, 800000)
plt.show()

타겟과 OverallQual의 데이터를 Boxplot으로 나타내었습니다. Boxplot에 대한 설명은 아래 글을 참고해주시길 바랍니다.
머신러닝(Machine Learning) 전반전 - 탐색적 데이터 분석(EDA) 실습
머신러닝 전반전 탐색적 데이터 분석(EDA): 데이터 파악 → 데이터 전처리: 결측치, 이상치 수정 → 데이터 인코딩: 데이터 변환 → 데이터 스케일링: 데이터 정규화 서론 탐색적 데이터 분석(Explor
10yp.tistory.com
Boxplot을 통해 이상치를 확인할 수 있고, 이 이상치를 사분위수를 이용해 처리하도록 하겠습니다.
Q1 = train['SalePrice'].quantile(0.25)
Q3 = train['SalePrice'].quantile(0.75)
IQR = Q3 - Q1
train = train[~((train['SalePrice'] < (Q1 - 1.5 * IQR)) | (train['SalePrice'] > (Q3 + 1.5 * IQR)))]
train.loc[(train['SalePrice'] < (Q1 - 1.5 * IQR)) | (train['SalePrice'] > (Q3 + 1.5 * IQR)), 'SalePrice'] = train['SalePrice'].median()
data = pd.concat([train['SalePrice'], train['OverallQual']], axis=1)
sns.boxplot(x=train['OverallQual'], y="SalePrice", data=data)
plt.ylim(0, 800000)
plt.show()
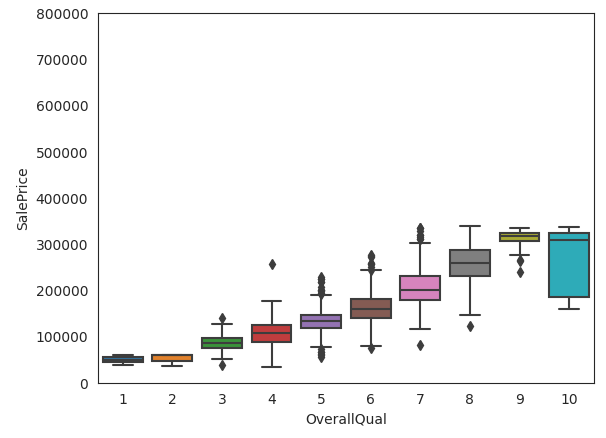
이렇게 이상치라고 판단되는 데이터들을 삭제하였습니다. 지금은 예시를 위해 진행하였으나, 실제로는 이와같은 데이터 삭제는 신중해야합니다. 타겟 데이터 자체가 삭제되는 것이기 때문에 다른 피처에 영향을 줄수도 있고, 이상치라고 판단하였으나, 사실은 중요한 데이터일수도 있기 때문입니다. 지금은 연습이기 때문에 그냥 진행하도록 하겠습니다.
다음은 TotalBsmtSF 피처에 대해 다뤄보겠습니다.
data = pd.concat([train['SalePrice'], train['TotalBsmtSF']], axis=1)
data.plot.scatter(x='TotalBsmtSF', y='SalePrice', alpha=0.3, ylim=(0,800000));
이전 전처리에 의해 데이터가 조금 삭제된 것이 보입니다. 여기서도 이상치라고 판단되는 데이터들을 적절히 제거해주겠습니다.
from scipy import stats
# Z-score 계산
z = np.abs(stats.zscore(train['TotalBsmtSF']))
# Z-score가 3 미만인 데이터만 선택
train = train[z < 3]
다시 그래프를 그려보면
data = pd.concat([train['SalePrice'], train['TotalBsmtSF']], axis=1)
data.plot.scatter(x='TotalBsmtSF', y='SalePrice', alpha=0.3, ylim=(0,800000));
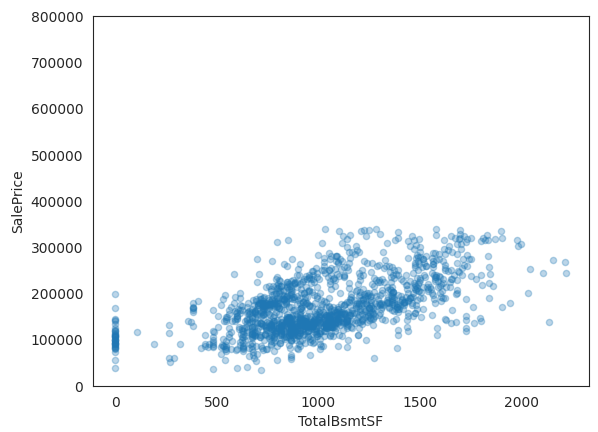
피처들에 대해 전처리가 마무리됐다면 이제는 결측치를 일괄적으로 처리하도록 합니다.
결측치 처리에는 다양한 방법이 있지만, 쉽게 수치형은 평균값을, 문자형은 최빈값으로 채워주도록 하겠습니다.
import pandas as pd
import numpy as np
# 수치형 피처 결측치 처리
for col in train.select_dtypes(include=np.number).columns:
train[col] = train[col].fillna(train[col].mean())
# 문자형 및 범주형 피처 결측치 처리
for col in train.select_dtypes(include=['object', 'category']).columns:
train[col] = train[col].fillna(train[col].mode()[0])
이런식으로 마무리 할 수 있습니다.
이후에는 범주형 데이터 인코딩, 데이터 스플릿, 모델 학습, 하이퍼파라미터 튜닝 등의 절차를 통해 모델을 학습시키고 예측하는 과정을 진행할 수 있습니다.
하지만
이렇게 많은 차원을 이런식으로 분석하는 것은 다소 시간이 많이 소요됩니다. 때문에, 다음 시간에는 좀 더 효율적으로 피처엔지니어링을 통해 차원을 줄이고, 주성분 분석을 통한 머신 러닝 진행을 다뤄보도록 하겠습니다.
'데이터 사이언스 > Kaggle' 카테고리의 다른 글
| 피처가 많을 때 머신러닝 어떻게 하나요 - 3편(PCA) (4) | 2024.03.12 |
|---|---|
| 피처가 많을 때 머신러닝 어떻게 하나요 - 1편 (73) | 2024.03.04 |
| 붓꽃 품종 분류 문제 데이터 로드부터 해결까지 Iris clustering (79) | 2024.01.16 |
| 캐글 실전 자전거 공유 수요 예측 (4) | 2024.01.12 |
| 캐글 실전 titanic 생존자 예측 (5) | 2024.01.11 |