


"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
서론
데이터 분석과 머신러닝은 점점 중요해지고 있는 분야입니다. 이들 분야에서 데이터는 가장 핵심적인 요소이며, 이 데이터를 어떻게 처리하고 분석하는지가 결과에 큰 영향을 미칩니다. 이 과정에서 데이터 전처리는 필수적인 단계로, 특히 데이터 스케일링은 모델의 성능을 크게 향상시키는 중요한 요소 중 하나입니다. 데이터 스케일링은 다양한 특성의 스케일 차이를 보정하거나, 이상치의 영향을 줄이는 등의 역할을 합니다. 이는 모델이 공정하게 각 특성을 학습할 수 있도록 돕는다는 점에서 매우 중요합니다. 그리고 이러한 스케일링은 Min-Max Scaling, Standard Scaling, Robust Scaling 등 다양한 방법으로 이루어질 수 있습니다. 이 글에서는 이러한 스케일링 방법들에 대해 설명하고, 각각의 방법을 파이썬 코드 예시와 함께 자세히 살펴보겠습니다. 이를 통해 데이터 스케일링의 중요성을 이해하고, 실제로 어떻게 적용하는지에 대한 방법을 배울 수 있을 것입니다. 이해가 어려운 개념도 직관적인 예시를 통해 쉽게 이해할 수 있도록 노력하겠습니다. 이제, 각 스케일링 방법에 대해 자세히 알아보도록 하겠습니다.
Min-Max Scaling (정규화)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
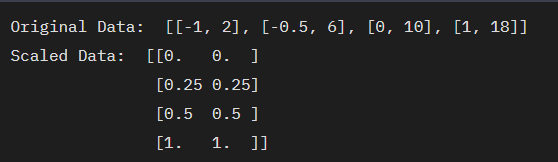
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
print("Original Data: ", data)
scaled_data = scaler.fit_transform(data)
print("Scaled Data: ", scaled_data)
이 코드는 sklearn의 MinMaxScaler 클래스를 사용하여 데이터를 정규화하는 과정을 보여줍니다. MinMaxScaler는 데이터를 0과 1 사이의 값으로 변환하므로, 이상치의 영향을 줄이고 다양한 특성의 스케일 차이를 보정하는데 효과적입니다.
예시 코드
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
print("Original Data: ", data)
scaled_data = scaler.fit_transform(data)
print("Scaled Data: ", scaled_data)
Standard Scaling (표준화)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data = [[0, 0], [0, 0], [1, 1], [1, 1]]
print("Original Data: ", data)
scaled_data = scaler.fit_transform(data)
print("Scaled Data: ", scaled_data)
이 코드는 sklearn의 StandardScaler 클래스를 사용하여 데이터를 표준화하는 과정을 보여줍니다. StandardScaler는 데이터의 평균을 0, 표준편차를 1로 만드는 방법으로, 각 특성의 분포를 비슷하게 만드는데 유용합니다.
예시 코드
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data = [[0, 0], [0, 0], [1, 1], [1, 1]]
print("Original Data: ", data)
scaled_data = scaler.fit_transform(data)
print("Scaled Data: ", scaled_data)

Robust Scaling (로버스트 스케일링)
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
data = [[1, 2], [1, 3], [2, 3], [2, 4], [3, 6], [4, 7]]
print("Original Data: ", data)
scaled_data = scaler.fit_transform(data)
print("Scaled Data: ", scaled_data)
이 코드는 sklearn의 RobustScaler 클래스를 사용하여 데이터를 스케일링하는 과정을 보여줍니다. RobustScaler는 이상치의 영향을 최소화하며, 데이터의 중앙값을 0, IQR(Interquartile range, 사분위수 범위)를 1로 스케일링합니다.
예시 코드
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
data = [[1, 2], [1, 3], [2, 3], [2, 4], [3, 6], [4, 7]]
print("Original Data: ", data)
scaled_data = scaler.fit_transform(data)
print("Scaled Data: ", scaled_data)
각 스케일링 방법은 데이터의 특성과 모델의 종류에 따라 다르게 적용될 수 있으며, 적절한 스케일링 방법을 선택하는 것이 중요합니다. 이는 데이터 분석과 머신러닝 모델의 성능을 크게 향상시킬 수 있는 중요한 요소입니다.
결론
데이터 분석과 머신러닝에서 데이터 전처리는 중요한 단계입니다. 특히, 데이터 스케일링은 모델의 성능에 큰 영향을 미치는 요소 중 하나입니다. 데이터를 적절한 범위로 변환하면, 이상치의 영향을 줄이고, 다양한 특성의 스케일 차이를 보정할 수 있습니다. 이 글에서는 세 가지 주요 스케일링 방법, 즉 Min-Max Scaling (정규화), Standard Scaling (표준화), Robust Scaling (로버스트 스케일링)의 코드 예시와 실행 결과를 살펴보았습니다. 각 방법은 데이터의 특성과 모델의 종류에 따라 다르게 적용될 수 있으며, 적절한 스케일링 방법을 선택하는 것이 중요함을 다시 한번 강조하고 싶습니다. 이론적인 지식뿐만 아니라, 실제 코드를 통한 실행 예시를 통해 이해를 돕고자 했습니다. 이를 통해 데이터 스케일링의 중요성을 이해하고, 실제로 어떻게 적용하는지에 대한 방법을 알게 되었기를 바랍니다. 이는 단지 한 가지 방법일 뿐, 데이터 전처리는 다양한 방법과 접근법이 필요한 분야입니다. 이 글이 복잡한 데이터 전처리 과정에서 여러분의 가이드가 되기를 바랍니다.
'데이터 사이언스 > 머신러닝 실습 전반전' 카테고리의 다른 글
| 머신러닝(Machine Learning) 실전 데이터 인코딩(Data Encoding) (77) | 2023.12.29 |
|---|---|
| 머신러닝(Machine Learning) 실전 데이터 전처리 (74) | 2023.12.29 |
| 머신러닝(Machine Learning) 실전 탐색적 데이터 분석(EDA) (5) | 2023.12.27 |
| 머신러닝(Machine Learning) 전반전 - 데이터 스케일링 실습 (49) | 2023.12.08 |
| 머신러닝(Machine Learning) 전반전 - 인코딩(Encoding) 실습 (57) | 2023.12.06 |