


"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
서론
데이터 과학과 머신러닝은 현대 사회에서 점점 중요해지고 있는 분야로, 이들 분야에서 중요한 역할을 하는 것이 바로 데이터 처리입니다. 특히, 범주형 데이터를 적절하게 처리하는 것은 머신러닝 모델의 성능에 큰 영향을 미칩니다. 이런 이유로, 이번 글에서는 실전 데이터 인코딩에 대한 핵심적인 개념과 주요 방법을 살펴보도록 하겠습니다. 본문에서는 레이블 인코딩, 원-핫 인코딩, 순서 인코딩, 이진 인코딩, 해시 인코딩, 타겟 인코딩 등 다양한 인코딩 방법을 파이썬 코드 예제와 함께 자세히 설명하겠습니다. 이전 글들을 참고하신다면 그 이해가 더 쉬우실 겁니다.
머신러닝(Machine Learning) 데이터 인코딩(Encoding) 기초
서론 머신러닝은 컴퓨터가 스스로 학습하여 문제를 해결하는 연구 분야로, 이를 위해선 데이터가 필수적입니다. 이 데이터는 다양한 형태와 형식으로 존재하며, 이를 컴퓨터가 이해할 수 있는
10yp.tistory.com
머신러닝(Machine Learning) 전반전 - 인코딩(Encoding) 실습
머신러닝 전반전 탐색적 데이터 분석(EDA): 데이터 파악 → 데이터 전처리: 결측치, 이상치 수정 → 데이터 인코딩: 데이터 변환 → 데이터 스케일링: 데이터 정규화 서론 데이터 과학의 세계에서,
10yp.tistory.com
실전 데이터 인코딩
실전 데이터 인코딩에 대한 설명과 그에 따른 코드 예시를 준비하였습니다. 이해를 돕기 위해 예시를 통해 설명을 추가하였습니다. 실전 데이터 인코딩 데이터 인코딩은 데이터 전처리 과정의 핵심 부분 중 하나로, 특히 범주형 데이터를 다룰 때 필수적입니다. 범주형 데이터는 '남성', '여성', '기타'와 같은 명목형 데이터 또는 '초등학교', '중학교', '고등학교', '대학교'와 같은 순서형 데이터를 포함합니다. 이러한 범주형 데이터는 그 자체로는 머신러닝 알고리즘에 직접 입력할 수 없으므로, 적절한 숫자형 데이터로 변환해야 합니다. 이렇게 범주형 데이터를 숫자형 데이터로 변환하는 과정을 '인코딩'이라고 합니다. 다음은 범주형 데이터를 다루는 데 자주 사용되는 인코딩 방법들입니다.
1. 레이블 인코딩(Label Encoding)
레이블 인코딩은 각 범주를 고유한 정수로 변환하는 가장 기본적인 방법입니다. 이 방법은 간단하고 직관적이지만, 범주 간의 순서 관계를 임의로 부여할 수 있다는 단점이 있습니다.
from sklearn.preprocessing import LabelEncoder
df = pd.DataFrame({'gender':['male', 'female', 'male', 'female', 'male']})
encoder = LabelEncoder()
df['gender_encoded'] = encoder.fit_transform(df['gender'])
print(df)
위의 코드는 'gender' 열의 'male'과 'female' 범주를 각각 1과 0으로 인코딩합니다. 결과적으로 'male'은 1로, 'female'은 0으로 변환됩니다.
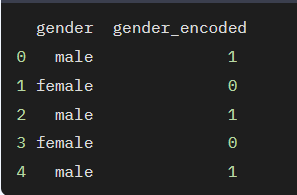
2. 원-핫 인코딩(One-Hot Encoding)
원-핫 인코딩은 각 범주를 고유한 이진 벡터로 변환하는 방법입니다. 이 방법은 범주 간의 순서 관계를 부여하지 않지만, 범주의 수가 많을 때는 데이터의 차원이 크게 증가한다는 단점이 있습니다.
df = pd.DataFrame({'gender':['male', 'female', 'male', 'female', 'male']})
df_encoded = pd.get_dummies(df, columns=['gender'])
print(df_encoded)
위의 코드는 'gender' 열의 'male'과 'female' 범주를 각각 [1, 0]과 [0, 1]의 이진 벡터로 인코딩합니다. 결과적으로 'male'은 [1, 0]으로, 'female'은 [0, 1]로 변환됩니다.

3. 순서 인코딩(Ordinal Encoding)
순서형 범주 데이터에 주로 사용되며, 범주 간의 순서 관계를 유지하면서 범주를 정수로 변환합니다. 예를 들어, '초등학교', '중학교', '고등학교', '대학교'와 같은 범주를 각각 1, 2, 3, 4로 변환하는 것입니다.
from sklearn.preprocessing import OrdinalEncoder
df = pd.DataFrame({'education':['primary', 'secondary', 'tertiary', 'quaternary']})
encoder = OrdinalEncoder(categories=[['primary', 'secondary', 'tertiary', 'quaternary']])
df['education_encoded'] = encoder.fit_transform(df[['education']])
print(df)
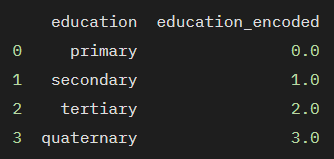
4. 이진 인코딩(Binary Encoding)
범주의 수가 많을 때 사용되며, 범주를 이진 코드로 변환합니다. 이 방법은 원-핫 인코딩에 비해 데이터의 차원을 크게 증가시키지 않으면서도 범주 간의 순서 관계를 부여하지 않는다는 장점이 있습니다.
import category_encoders as ce
df = pd.DataFrame({'country':['Korea', 'Japan', 'China', 'USA', 'Canada', 'Brazil', 'Argentina']})
encoder = ce.BinaryEncoder(cols=['country'])
df_encoded = encoder.fit_transform(df)
print(df_encoded)
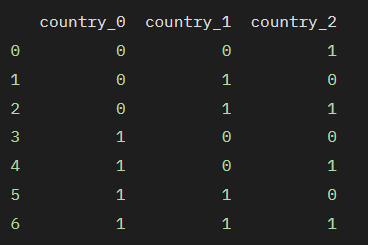
5. 해시 인코딩(Hashing Encoding)
범주의 수가 매우 많거나 범주의 수를 사전에 알 수 없을 때 사용되며, 범주를 해시 함수를 통해 정수로 변환합니다. 이 방법은 범주의 수가 많아도 데이터의 차원을 제어할 수 있지만, 해시 충돌이 발생할 가능성이 있다는 단점이 있습니다.
encoder = ce.HashingEncoder(n_components=5)
df_encoded = encoder.fit_transform(df)
print(df_encoded)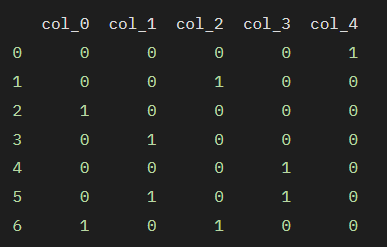
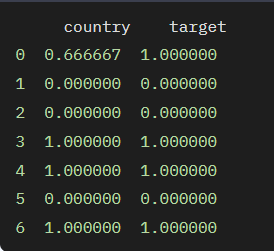
6. 타겟 인코딩(Target Encoding)
범주를 타겟 변수의 평균값으로 변환하는 방법으로, 주로 회귀 문제나 이진 분류 문제에서 사용됩니다. 이 방법은 범주 간의 차이를 더 잘 반영할 수 있지만, 오버피팅(과적합)을 일으킬 수 있다는 단점이 있습니다.
df = pd.DataFrame({'country':['Korea', 'Japan', 'China', 'USA', 'Canada', 'Brazil', 'Argentina'],
'target':[1, 0, 0, 1, 1, 0, 1]})
encoder = ce.TargetEncoder(cols=['country'])
df_encoded = encoder.fit_transform(df['country'], df['target'])
print(df_encoded)
이러한 과정을 통해 머신러닝 모델의 성능을 높일 수 있습니다. 다음으로 실전 데이터를 이용한 인코딩 예제를 살펴보도록 하겠습니다. 해당 예제에서는 타이타닉 데이터 셋을 이용하여 생존 예측 모델을 만들어보는 과정에서 필요한 범주형 데이터를 인코딩하는 과정을 다룹니다.
실전 데이터 인코딩 예제 - 타이타닉 생존 예측 모델
import pandas as pd
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
# 데이터 로딩
titanic = pd.read_csv('titanic.csv')
# Label Encoding 예제
le = LabelEncoder()
titanic['Sex'] = le.fit_transform(titanic['Sex'])
# One-Hot Encoding 예제
ohe = OneHotEncoder()
titanic_encoded = pd.DataFrame(ohe.fit_transform(titanic[['Embarked']]).toarray(),
columns=['Embarked_C', 'Embarked_Q', 'Embarked_S'])
titanic = pd.concat([titanic, titanic_encoded], axis=1)
이 코드는 타이타닉 데이터 셋에서 'Sex'는 레이블 인코딩을, 'Embarked'는 원-핫 인코딩을 적용한 예제입니다. 'Sex' 열은 'male'과 'female' 두 가지 범주만을 가지므로 레이블 인코딩을 적용하였고, 'Embarked' 열은 세 가지 이상의 범주를 가지므로 원-핫 인코딩을 적용하였습니다. 이렇게 데이터의 특성에 따라 적절한 인코딩 방법을 선택하는 것이 중요합니다.
결론
실전 데이터 인코딩은 머신러닝 모델의 성능을 크게 좌우하는 중요한 과정입니다. 본문에서는 다양한 인코딩 방법을 설명하고, 이를 실전 데이터에 적용하는 방법을 타이타닉 생존 예측 모델을 통해 실습해보았습니다. 이를 통해 각 인코딩 방법의 특성과 적절한 활용 방법을 이해할 수 있었습니다. 앞으로도 머신러닝 모델을 개발하고 개선하는 데 있어, 이번에 배운 내용을 잘 활용하시길 바랍니다. 추가적인 질문이나 더 깊은 이해를 위해 필요한 자료가 있다면, 언제든지 문의해주세요. 이 글을 통해 실전 데이터 인코딩에 대한 이해가 깊어졌기를 바랍니다.
'데이터 사이언스 > 머신러닝 실습 전반전' 카테고리의 다른 글
| 머신러닝(Machine Learning) 실전 데이터 스케일링 (67) | 2024.01.01 |
|---|---|
| 머신러닝(Machine Learning) 실전 데이터 전처리 (74) | 2023.12.29 |
| 머신러닝(Machine Learning) 실전 탐색적 데이터 분석(EDA) (5) | 2023.12.27 |
| 머신러닝(Machine Learning) 전반전 - 데이터 스케일링 실습 (49) | 2023.12.08 |
| 머신러닝(Machine Learning) 전반전 - 인코딩(Encoding) 실습 (57) | 2023.12.06 |